目录
简介
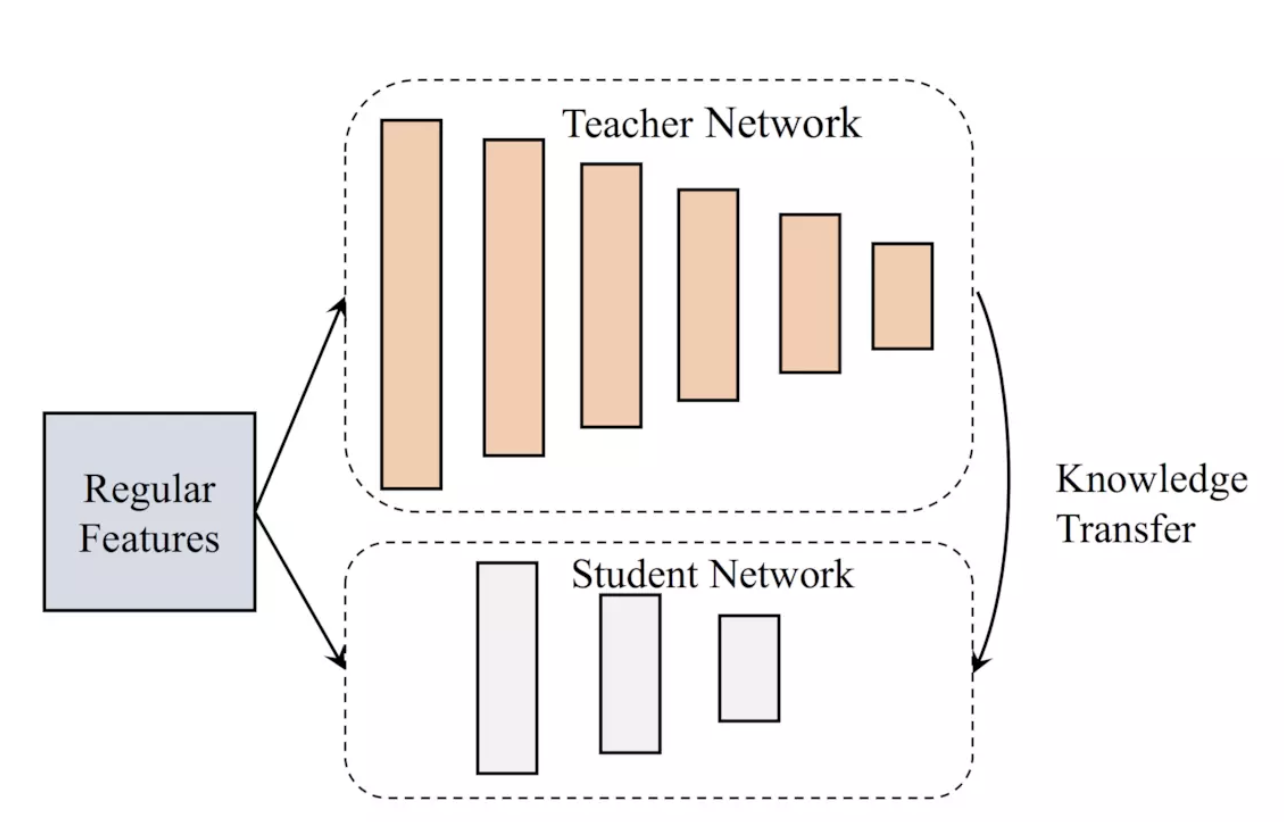
知识蒸馏被广泛的用于模型压缩和迁移学习当中。
训练一个复杂的Teacher网络和一个简单的Student网络,并通过Teacher网络来在一定程度上指导Student网络的学习。对于模型蒸馏Model Distillation来说,两个网络的输入是相同的,只是Teacher网络的模型结构更加复杂。
架构
实现
self.teacher_predict = tf.sigmoid(self.teacher_logits)
self.teacher_loss = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=self.teacher_logits, labels=self.label))
self.prerank_loss = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=self.logits, labels=self.label))
self.distil_loss = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=self.logits, labels=self.teacher_predict))
self.loss = self.prerank_loss + self.distil_loss + self.teacher_loss + self.reg_loss参考
- Geoffrey Hinton《Distilling the Knowledge in a Neural Network》
- 《Distilling Task-Specific Knowledge from BERT into Simple Neural Networks》