论文总结
《Mixture of Virtual - Kernel Experts for Multi - Objective User Profile Modeling》论文总结
-
摘要:
- 提出了一种名为Mixture of Virtual - Kernel Experts(MVKE)的多任务模型,用于高效、准确和全面地学习用户在各种行动和主题上的偏好,以解决在线广告和推荐系统中用户画像的挑战。
-
相关工作:
- 在线预测模型:应用神经网络进行在线预测任务,如点击预测、内容排名等,Two - Tower模型因其高效的预测效率被广泛应用,同时也有许多关于模型结构改进的工作。
- 多任务学习模型:包括硬参数共享、交叉缝合、闸口网络和注意力机制等方法,一些模型还专注于任务目标的设计,如ESMM模型用于处理样本选择偏差。
-
预备知识:
- 形式化定义:定义了用户、广告、点击动作集、转换动作集等概念,以及用户兴趣标签、用户意图标签和用户标签的定义,介绍了基本的Two - Tower模型架构和损失函数。
- 基本解决方案:目前通过构建两个独立的模型分别挖掘用户的兴趣和意图标签,但这种方法无法有效地产生多目标标签,且牺牲了一定的准确性。
-
MVKE模型:
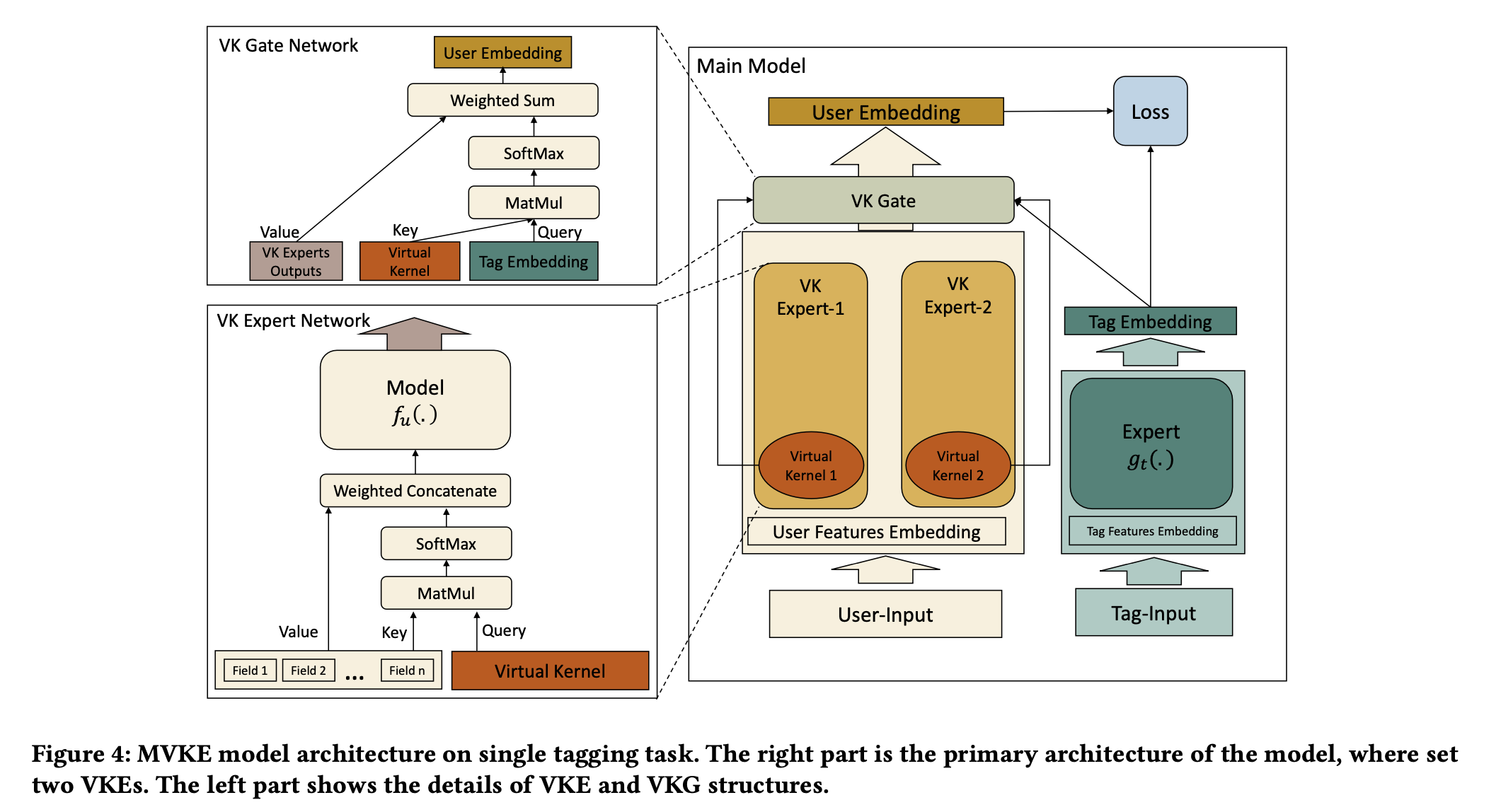
- 单任务:MVKE是一个类似于Two - Tower的模型,通过Virtual - Kernel Experts(VKE)和Virtual - Kernel Gate(VKG)打破了两个塔之间的障碍。VKE专注于用户偏好的一个特定方面,VKG根据标签嵌入和虚拟内核有选择地组合VKE的输出,以生成特定于标签的用户表示。
- 多任务:可以设置更多的VKE来服务不同的任务,一个VKG服务一个特定的任务,模型的最终损失函数是各个任务损失的总和。
- 快速预测:MVKE保留了Two - Tower模型快速预测的特点,其推理时间复杂度为,空间复杂度为,其中是VKE的数量。
- 分析与讨论:与其他模型相比,MVKE通过虚拟内核能够更准确地表示用户,不同的VKE可以更具差异化地建模用户偏好的特定方面,同时加强了两个塔之间的信息融合。
-
实验:
- 实验设置:使用从腾讯广告日志中收集的用户行为记录构建数据集,与noMTL、Hard Sharing、MoE、MMoE、CGC等基线模型进行比较,评估指标包括离线阶段的AUC和在线阶段的GMV、Adjust Cost等。
- 离线结果:MVKE - mt在大多数情况下优于noMTL约0.2%至0.9%,并且优于其他所有MTL模型;MVKE - st在处理主题维度的建模方面表现良好,能够比noMTL高出约0.1%至0.7%,甚至优于所有MTL模型。
- 在线A / B测试结果:MVKE在50%阶段帮助GMV提升0.79%,Adjust Cost提升0.51%,意味着广告商和广告平台每天都能增加数百万人民币的收入;MVKE - both的提升效果优于MVKE - intention,MVKE - intention优于MVKE - interest,表明MVKE对意图标签(pCVR)任务的益处更多。
-
结论:
-
MVKE模型能够有效应对数据规模大、主题目标多样和行动目标多样等挑战,通过引入Virtual - Kernel Experts(VKE)和Virtual - Kernel Gate(VKG),增强了用户偏好的准确性和多样性,显著提高了腾讯广告的性能。
-
综上所述,本文提出的MVKE模型在用户画像任务中具有显著的优势,能够为在线广告和推荐系统提供更精准的用户画像,从而提高个性化服务的质量。
-
模型结构图
参考
- https://www.jianshu.com/p/f3ef5fceacce