论文地址
[2305.05065] Recommender Systems with Generative Retrieval
论文介绍
“Recommender Systems with Generative Retrieval”提出了一种新的生成式检索推荐框架TIGER,通过为每个项目分配语义ID,并使用基于Transformer的序列到序列模型预测用户可能感兴趣的项目的语义ID,在多个数据集上取得了优于现有SOTA模型的性能。
-
研究背景
- 现代推荐系统通常采用检索和排序策略,其中检索模型的性能对推荐结果至关重要。
- 传统的检索模型主要基于查询-候选匹配方法,存在一些局限性,如难以处理语义信息、对新物品的泛化能力较差等。
-
相关工作
- 顺序推荐器:介绍了多种基于深度学习的顺序推荐模型,如GRU4REC、NARM、SASRec等,这些模型主要学习每个项目的高维嵌入,并在最大内积搜索空间中进行近似最近邻搜索来预测下一个项目。
- 语义ID:提到了一些生成语义ID的相关工作,如VQ - Rec,但这些工作主要关注构建可迁移的推荐系统,没有将语义ID用于生成式检索。
- 生成式检索:介绍了一些文档检索中的生成式检索方法,如GENRE、DSI等,但这些方法没有应用于推荐系统。
-
TIGER框架
-
语义ID生成
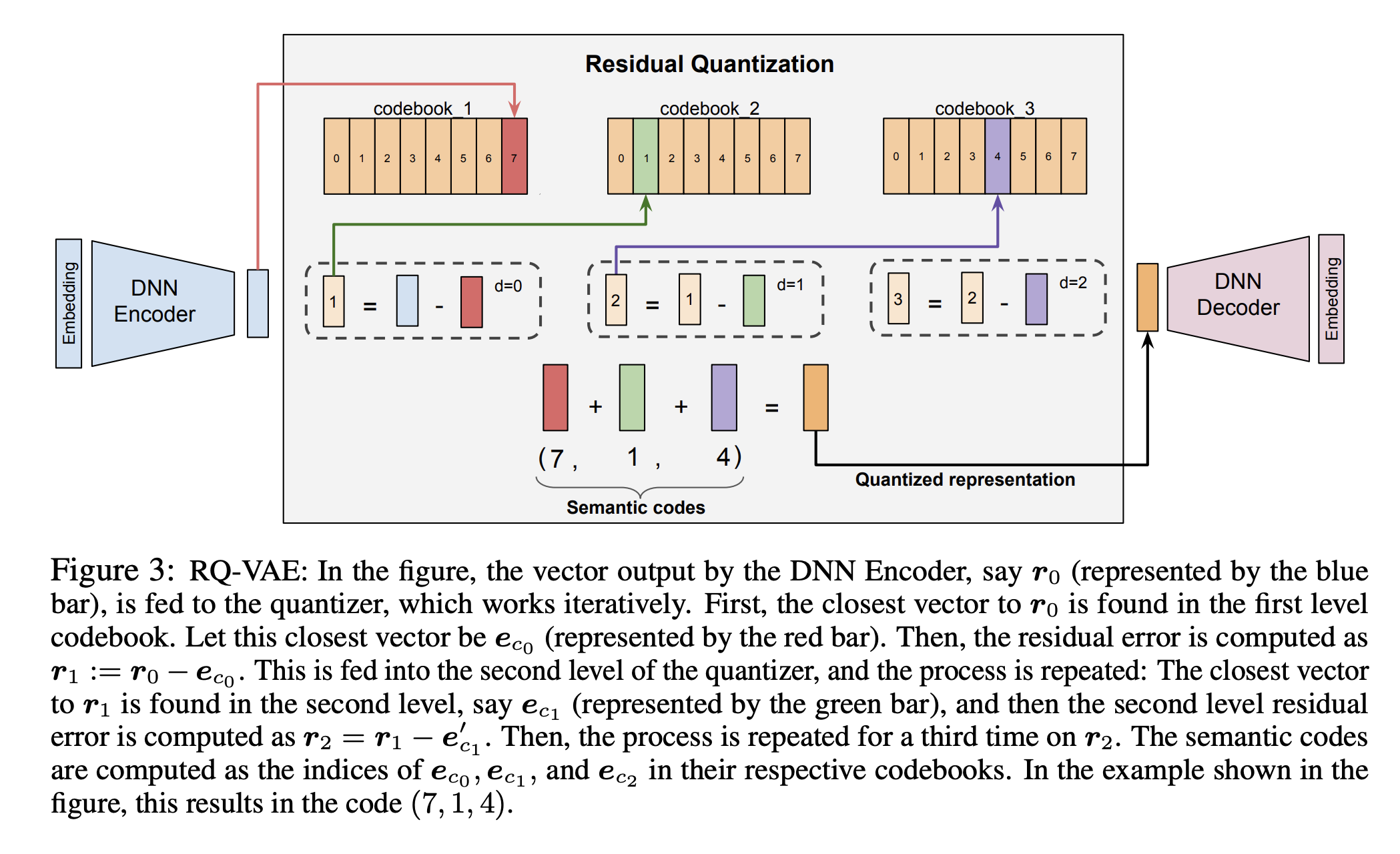
- 使用预训练的内容编码器(如Sentence - T5)将项目的文本特征转换为语义嵌入,然后使用RQ - VAE对语义嵌入进行量化,生成语义ID。
- RQ - VAE是一种多级向量量化器,通过对残差进行量化来生成语义ID,可以有效地处理语义嵌入的非线性特性。
-
为了避免语义冲突,在语义ID的末尾添加一个额外的标记,使其具有唯一性。
- 基于语义ID的生成式检索
-
将用户的项目交互历史转换为语义ID序列,然后使用基于Transformer的序列到序列模型预测下一个项目的语义ID。
- 在训练过程中,模型学习预测语义ID的概率分布,在推理过程中,使用束搜索生成最可能的语义ID。
-
-
实验结果
- 数据集和评估指标:使用了亚马逊产品评论数据集中的三个类别(“Beauty”、“Sports and Outdoors”、“Toys and Games”)进行实验,评估指标包括top - k Recall和Normalized Discounted Cumulative Gain。
- 性能比较:与多种顺序推荐方法进行比较,TIGER在所有三个数据集上均取得了更好的性能。
-
项目表示分析
- 通过定性分析验证了RQ - VAE语义ID的层次结构特性,这种特性有助于模型更好地理解项目之间的语义关系。
-
通过对比实验证明了RQ - VAE在语义ID生成方面优于基于哈希的量化方法(LSH),以及语义ID相对于随机ID在推荐性能上的优势。
- 新能力展示
-
在冷启动推荐场景中,TIGER能够利用项目语义信息有效地推荐新物品,优于k - 近邻方法。
- 通过在解码过程中使用基于温度的采样方法,可以控制模型预测的多样性,提高推荐结果的丰富度。
-
研究结论
- TIGER框架通过使用生成式检索和语义ID表示,在推荐系统中取得了良好的性能,能够有效地处理语义信息,提高对新物品的泛化能力,并实现推荐结果的多样性。
- 未来的工作可以进一步探索如何提高模型的计算效率,以及如何更好地利用语义ID的层次结构特性进行推荐。