前言
OneRec是近期比较火的端到端推荐的文章,OneRec框架开创性地将推荐系统的检索与排序阶段统一为端到端生成模型。在快手亿级用户场景中验证,线上A/B测试显著提升1.6%用户观看时长,为工业级推荐系统提供突破级解决方案。其会话式列表生成机制突破传统point-wise推荐范式,提出的平衡量化编码和DPO优化方法对多模态推荐、强化学习对齐等领域具有重要借鉴意义。
引言:传统推荐系统的困境
传统推荐系统采用"召回-粗排-精排"的级联架构,每个阶段独立优化,存在明显的效率瓶颈。这种"流水线"式设计导致:
- 误差累积:每个环节的误差逐级放大
- 上下文割裂:各阶段目标不一致导致推荐结果不连贯
- 工程复杂度高:多模块协同带来维护成本
快手团队提出的OneRec通过生成式推荐范式,将传统多阶段流程统一为端到端的生成模型,在快手主场景实现观看时长提升1.6%的重大突破。
相关工作
生成式推荐将推荐问题视为序列生成任务,通过语义索引技术提升推荐性能。语言模型偏好对齐常用强化学习从人类反馈(RLHF),但存在不稳定和低效问题。直接偏好优化(DPO)可直接用偏好数据优化,在推荐系统中应用面临用户 - 项目交互数据稀疏的挑战。
OneRec技术方案
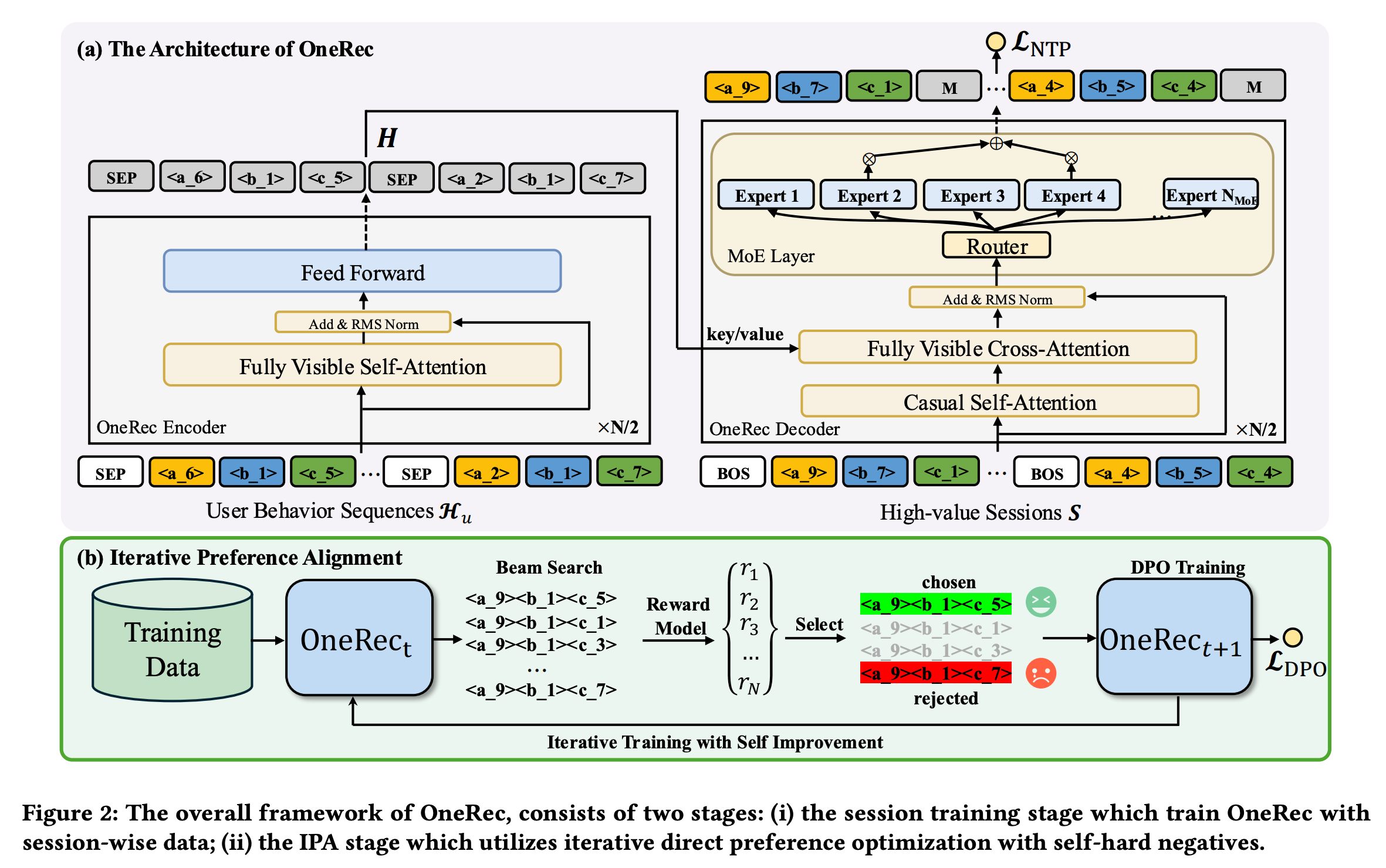
整个OneRec框架包括两阶段:
- The Session Training Stage:训练序列生成的模型$OneRec_t$
- The IPA Stage:使用Reward Model迭代优化$OneRec_t$模型的生成效果
平衡码本构建
以用户历史行为序列为输入,用多层平衡量化机制将视频多模态嵌入转换为语义令牌,构建平衡码本,这一步主要是对推荐的item进行残差编码,得到多层的语义ID,当层次够多时继续可以做到和ID一一对应。
-
用户侧特征与系统输出:OneRec以用户的正向历史行为序列$H_{u}={v_{1}^{h}, v_{2}^{h}, \cdots, v_{n}^{h}}$作为输入,其中$v$代表用户有效观看或互动(点赞、关注、分享)过的视频,$n$为行为序列长度。其输出是一个由会话$S={v_{1}, v_{2}, \cdots, v_{m}}$构成的视频列表,$m$是一个会话中的视频数量,“会话”的详细定义在3.2节。
-
视频特征表示:对于每个视频$v_i$,使用多模态嵌入$e_{i} \in \mathbb{R}^{d}$描述,该嵌入与真实用户 - 物品行为分布一致。多模态嵌入综合了视频的多种模态信息,让模型更全面理解视频内容,以匹配用户偏好。
-
语义令牌生成:现有生成式推荐框架常基于预训练多模态表示,用RQVAE将嵌入编码为语义令牌。但由于存在代码分布不平衡的“沙漏现象”,这种方法并非最优。OneRec采用多层次平衡量化机制和残差K - 均值量化算法转换$e_{i}$。在第一层($l = 1$),初始残差$r_{i}^{1}=e_{i}$,每一层都有一个码本$C_{l}={c_{1}^{l}, \cdots, c_{K}^{l}}$($K$为码本大小),通过 $s_{i}^{l}=\arg\min_{k}\left|r_{i}^{l}-c_{k}^{l}\right|{2}^{2}$ 生成最近质心节点嵌入的索引,下一层的残差$r^{l + 1}=r_{i}^{l}-c_{s_{i}^{l}}^{l}$,并通过分层索引生成相应的码本令牌。
-
平衡码本构建:通过平衡K - 均值算法(见算法1)构建平衡码本$C_{l}$。该算法将总视频集$V$划分为$K$个簇,每个簇包含$w = |V| / K$个视频。在迭代计算中,基于欧氏距离为每个质心依次分配$w$个最近的未分配视频,然后用分配视频的均值向量重新校准质心,当簇分配达到收敛时终止。
Balanced K-means Clustering(平衡K均值聚类算法)
Balanced K-means Clustering(平衡K均值聚类算法)是用于构建平衡码本的关键方法,旨在优化给定簇大小下的均方误差,实现平衡聚类,使每个簇的大小相等。该算法在OneRec模型的视频特征处理中发挥着重要作用,能够有效提升推荐系统的性能。下面从算法原理、应用场景、优势及与其他算法的对比等方面详细介绍:
-
算法原理
- 初始化:在给定总视频集$V$和簇数量$K$的情况下,计算每个簇应包含的视频数量$w = |V| / K$。随机选取$K$个点作为初始质心,每个质心代表一个簇的中心。
- 分配步骤:将每个视频分配到距离其最近的质心所在的簇中。具体计算视频特征与质心之间的距离,通常使用欧氏距离衡量,如$d = \sqrt{\sum_{i = 1}^{n}(x_i - y_i)^2}$ ,其中$(x_1, x_2, \cdots, x_n)$和$(y_1, y_2, \cdots, y_n)$分别表示视频特征和质心的坐标。
- 更新步骤:对于每个簇,重新计算质心的位置。将簇内所有视频特征的均值作为新的质心,即新质心的坐标为簇内所有视频特征坐标的平均值。
- 迭代收敛:重复分配和更新步骤,直到质心位置不再改变或变化极小,或者达到预定的迭代次数,此时算法收敛,完成聚类。
-
应用场景
- 推荐系统的码本构建:在OneRec模型中,用于对视频的多模态嵌入进行量化,构建平衡码本。通过平衡K均值聚类,将视频特征划分为不同的簇,每个簇对应一个码本中的码,使得码本中的码分布更加均衡,有效解决传统RQVAE编码中出现的“沙漏现象”,提升推荐系统对视频特征的表示能力,进而提高推荐的准确性和多样性。
- 数据均衡场景:在其他需要数据均衡的场景中也有应用,如在任务分配中,希望将任务均匀分配到不同的处理单元,使每个单元的工作量均衡;在图像分割中,使分割后的各个区域大小相对均衡 。
-
优势
- 优化均方误差:以优化均方误差为目标,能使同一簇内的数据点相似度高,不同簇的数据点差异大,保证聚类质量,在推荐系统中可使属于同一码本簇的视频特征更相似,便于模型学习和区分不同类型的视频。
- 实现平衡聚类:可以确保每个簇的大小相等,避免出现某些簇过大或过小的情况,在推荐系统中有助于均匀地覆盖不同类型的视频,防止某些类型视频在码本中过度或过少表示,提升推荐的全面性。
- 高效处理大数据集:在K均值聚类的分配阶段,使用匈牙利算法解决分配问题,使分配阶段的时间复杂度为$O(n^3)$,相比之前约束K均值中使用的时间复杂度为$O(k^{3.5}n^{3.5})$的线性规划方法,效率更高,能够处理规模超过5000个点的更大数据集,满足大规模推荐系统的数据处理需求。
-
与其他聚类算法对比
- 与传统K均值聚类:传统K均值聚类不保证簇大小相等,可能导致聚类结果不均衡,在推荐系统中会使某些视频类型的推荐权重失衡。而平衡K均值聚类通过约束簇大小,实现更均衡的聚类,提升推荐的公平性和全面性。
- 与其他平衡聚类算法:如频率敏感竞争学习(FSCL)算法,通过对质心到数据点的距离进行调整来平衡聚类,但方式较为间接。平衡K均值聚类则直接以优化均方误差和平衡簇大小为目标,算法思路更直接,在处理大规模数据集时效率更高 。
会话式列表生成
区别于传统逐点推荐,生成高价值会话列表。模型采用基于Transformer的编码器 - 解码器框架,解码器用MoE架构提升计算效率,训练时用交叉熵损失。
-
核心目标:区别于传统逐点推荐仅预测下一个视频,会话式列表生成旨在依据用户历史交互序列,生成高价值的视频会话列表,使推荐模型能捕捉推荐列表中视频间的依赖关系。一个会话通常包含5 - 10个短视频,这些视频需综合考虑用户兴趣、连贯性和多样性等因素。高质量会话需满足用户实际观看短视频数量不少于5个、观看总时长超过特定阈值、用户有互动行为(点赞、收藏、分享)等条件。
-
模型架构:采用基于Transformer的框架,包含编码器和解码器。编码器利用堆叠的多头自注意力和前馈层处理用户历史交互序列$H_{u}$,得到编码后的历史交互特征$H = Encoder(H_{u})$ 。解码器以目标会话的语义ID为输入,自回归生成目标。为在合理成本下训练更大模型,解码器的前馈神经网络(FNNs)采用MoE架构,将第$l$层FFN替换为特定公式计算,通过门控机制使每个token仅在$K_{MoE}$个专家中计算,提升计算效率。
-
训练过程:在训练时,在代码开头添加起始标记$s_{[BOS]}$构建解码器输入。使用交叉熵损失进行目标会话语义ID的下一个令牌预测,计算NTP损失($\mathcal{L}{NTP}$)。经过一定训练后,得到种子模型$M$。
基于奖励模型的迭代偏好对齐
训练会话式奖励模型选择偏好数据,基于预训练奖励模型和当前模型生成不同响应,构建偏好对,通过迭代直接偏好优化更新模型。构建偏好对时,用到了beam search,这里beam search具体细节,看原文中也没详细介绍,读者大概知道其生成若干候选构造pair的目的就可以了。
-
面临挑战与解决方案:3.2节定义的高质量会话为模型训练提供了有价值数据,但为进一步提升模型能力,需进行直接偏好优化(DPO)。在传统自然语言处理中,偏好数据由人工标注,而推荐系统中用户 - 项目交互数据稀疏,因此需要引入会话式奖励模型(RM)。
-
3.3.1 Reward Model Training(奖励模型训练):用$R(u, S)$表示奖励模型,其输出$r$代表用户$u$对会话$S$的偏好奖励。为使RM具备会话排序能力,先提取会话$S$中每个项目$v_{i}$的目标感知表示$e_{i}=v_{i} \odot u$ ,得到会话的目标感知表示$h$。通过自注意力层让会话中的项目相互作用融合信息,再利用不同塔对多目标奖励进行预测。用丰富的推荐数据预训练RM,通过最小化二元交叉熵损失训练。
-
3.3.2 Iterative Preference Alignment(迭代偏好对齐):基于预训练的RM和当前OneRec模型$M_{t}$,通过束搜索为每个用户生成$N$个不同响应。用RM计算每个响应的奖励$r_{u}^{n}$ ,选择奖励最高和最低的响应构建偏好对$D_{t}^{pairs }=(S_{u}^{w}, S_{u}^{l}, H_{u})$ 。利用偏好对训练新模型$M_{t + 1}$,其损失函数结合了DPO损失。在训练过程中,为减轻束搜索推理的计算负担,随机采样1%的数据进行偏好对齐,新模型$M_{t + 1}$从$M_{t}$初始化,利用$M_{t}$生成的偏好数据训练。
系统部署
在工业场景部署OneRec - 1B模型,包括训练系统、在线服务系统和DPO样本服务器。训练时结合XLA和bfloat16混合精度训练,推理时采用关键值缓存解码和float16量化等优化技术。
实验评估
-
实验设置:用Adam优化器训练模型,以多个模型和DPO变体为基线,用多个指标评估模型性能。
-
实验结果:OneRec的会话式生成方法优于传统方法;少量DPO训练可显著提升性能;IPA策略优于其他DPO变体;1%的DPO样本比在计算效率和性能间平衡最佳;模型规模扩大时性能提升;在线A/B测试显示OneRec提升了用户观看时长和平均观看时长。
线上效果
- 在快手的主要场景部署,观看时长+1.6%。
优化点总结
-
提出优于point-wise的list-wise生成方式
-
提出优于其他DPO方法的迭代偏好对齐IPA方法
文章链接
前置知识点
本文涉及到一些前置知识点,以下初步列了一些需要准备的前序知识,感兴趣的可以阅读下: