论文介绍
MARM 论文详细总结
1. 研究背景与动机
-
推荐系统与LLM的差异:
- 数据规模:推荐系统每天处理数十亿用户行为数据(如快手500亿/天),远超LLM训练数据。
- 模型参数:推荐系统参数(>200B)超过多数LLM(约100B),但需严格控制推理复杂度(FLOPs)以保证实时性(毫秒级响应)。
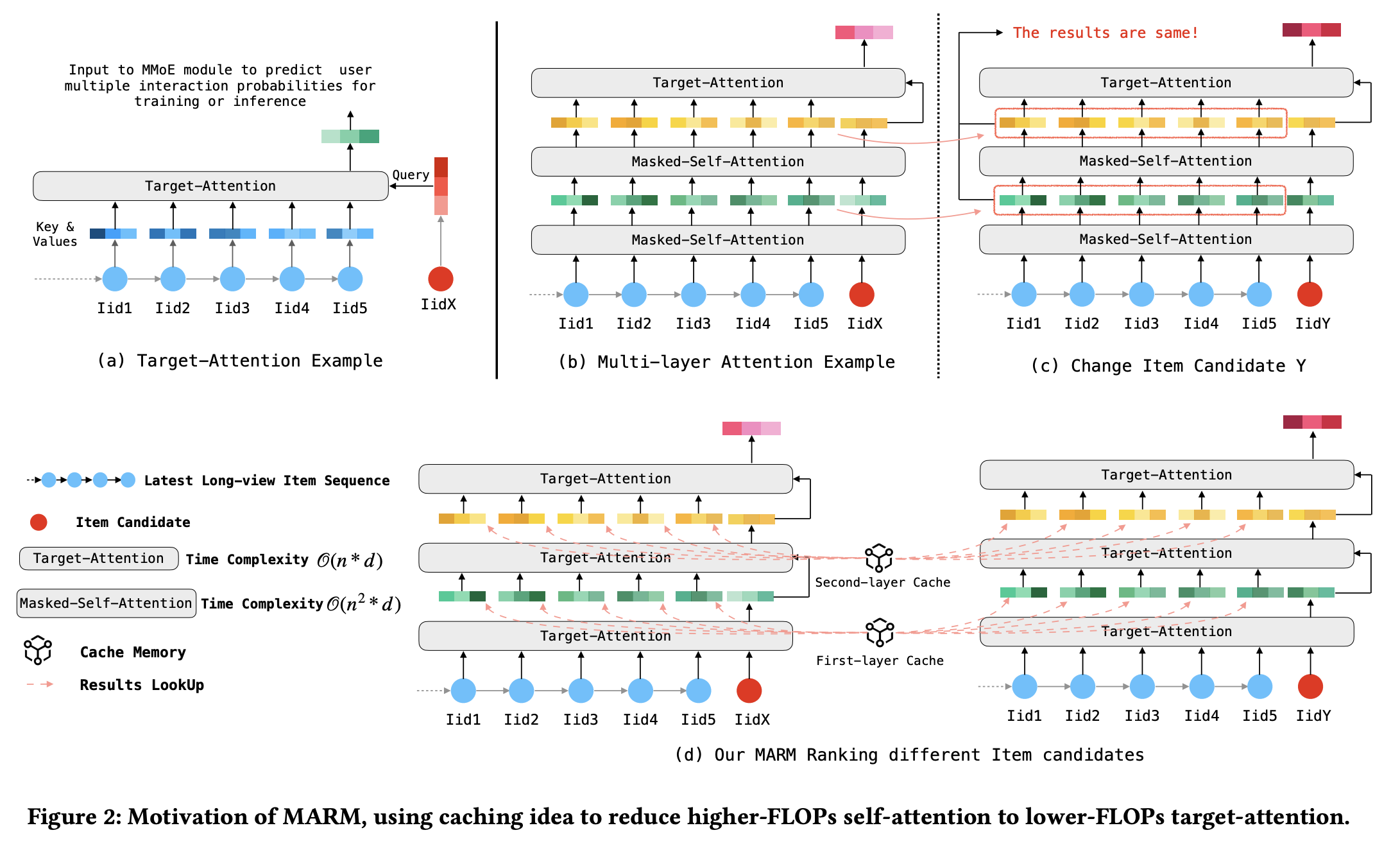
- 计算瓶颈:传统注意力机制(如自注意力)的时间复杂度为 ,无法直接扩展到长序列(如用户历史行为序列)。
-
核心挑战:
- 如何在不显著增加计算成本的前提下,提升推荐模型的表达能力。
- 如何利用推荐系统的海量数据和存储资源优势,缓解计算资源的限制。
2. MARM 模型设计
-
核心思想:
- 缓存技术:通过缓存多层注意力的中间结果,将复杂的自注意力()转换为目标注意力(),降低推理复杂度。
- 可扩展架构:将单层目标注意力扩展为多层,通过缓存实现线性复杂度增长。
-
模块组成:
-
序列生成器:生成用户最新曝光的物品序列。
- 缓存存储:存储历史计算结果,支持快速查询。
- 多层目标注意力:通过缓存结果模拟多层自注意力,逐层更新特征表示。
-
结果保存:将中间结果存入缓存,供后续推理使用。
-
与SIM的结合:
- 引入两阶段搜索(GSU/ESU)处理超长序列(如用户终身行为),提升缓存利用率。
- 每层独立搜索相关历史,减少层间冗余,增强兴趣表达多样性。
3. 缓存扩展定律
-
缓存规模与性能关系:
- 缓存大小:定义为 (L为层数,n为序列长度,d为维度),与模型性能呈幂律关系。
-
关键发现:
- 当缓存规模较小时,增加序列长度(n)比增加层数(L)更有效。
- 当缓存规模足够大时,层数和序列长度的贡献趋于平衡。
-
实验验证:
- 通过离线实验验证缓存规模与GAUC的正相关关系,证明MARM的可扩展性。
4. 实验结果
-
离线对比:
- 基线模型:基于多任务MoE的工业级模型。
- 对比方法:DIN、SIM、TWIN、TWIN V2、HSTU等。
- 结果:MARM(L=4)在GAUC上提升0.43%,AUC提升0.19%,显著优于其他方法。
-
在线效果:
-
在快手国际版(Kwai)部署,实现:
- 核心指标:用户平均观看时长增加2.079%。
- 互动指标:点赞率提升0.605%,但评论、转发略有下降(属合理替代效应)。
-
-
成本分析:
- 存储需求:60TB(L=4,n=6000),仅为原始多层自注意力的1/8。
- 计算效率:推理FLOPs显著低于HSTU(未缓存版本)。
5. 贡献与创新
-
首次提出缓存扩展定律:在推荐系统中探索缓存规模与性能的关系,突破传统模型复杂度限制。
-
高效架构设计:通过缓存技术将多层自注意力转换为线性复杂度,支持用户终身行为建模。
-
工业级适配:无缝集成现有推荐系统(检索、粗排、精排),实现端到端优化。
6. 应用场景
-
实时推荐:快手短视频平台,每日服务数亿用户。
-
长序列建模:支持用户终身行为分析,捕捉长期兴趣演变。
-
多阶段优化:在检索、粗排、精排各阶段均提升效果。
7. 结论
MARM通过缓存技术和多层注意力机制,成功解决了推荐系统的计算瓶颈问题,在保持高效推理的同时显著提升模型性能。其提出的缓存扩展定律为推荐系统的可扩展设计提供了新范式,未来可进一步探索与其他技术(如稀疏缓存、动态存储管理)的结合。