“ReLLa: Retrieval-enhanced Large Language Models for Lifelong Sequential Behavior Comprehension in Recommendation”由Jianghao Lin等人撰写。文章提出ReLLa框架,通过语义用户行为检索(SUBR)和检索增强指令调整(ReiT),解决大语言模型在推荐任务中对长用户行为序列理解不足的问题,提升零样本和少样本推荐性能。
-
研究背景:推荐系统对缓解信息过载至关重要,大语言模型(LLMs)在自然语言处理领域成果显著,二者结合的研究成为热点。但LLMs在推荐领域存在对长用户行为序列理解不足的问题,即便上下文长度未达上限,也难以提取有用信息。
-
预备知识
- 零样本和少样本推荐:零样本推荐指模型未经领域内训练直接用于目标推荐任务;少样本推荐是在少量训练样本下的推荐任务,与之相对的是基于完整训练集的全样本推荐。
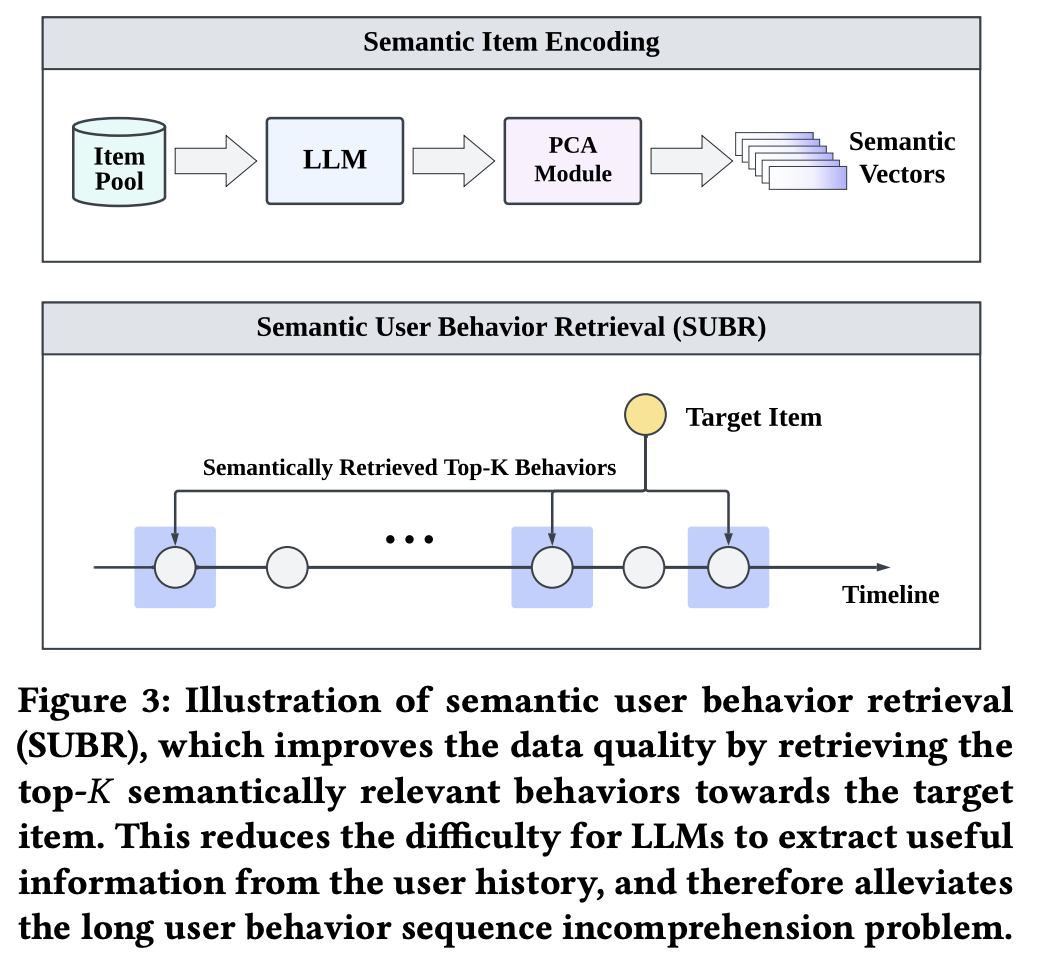
- 文本输入 - 输出对构建:将数据样本和标签转化为文本形式,利用硬提示模板构建输入 - 输出对,关键在于用户行为序列处理,ReLLa采用语义用户行为检索代替传统截断方式。
- 使用LLMs进行逐点评分:LLMs输出经处理用于CTR预测,训练时保持其指令调整和因果语言建模范式,测试时用特定方法估计点击率。
-
方法
- ReLLa框架概述:针对零样本推荐,使用SUBR提升数据样本质量;针对少样本推荐,通过ReiT增强LLMs处理长行为序列的能力,采用SUBR扩充训练数据。
- 语义用户行为检索(SUBR):在零样本设置下,用SUBR替换近期K行为,通过语义项编码和PCA降维获取语义向量,计算相似度检索相关行为,提升零样本推荐性能。
- 检索增强指令调整(ReiT):少样本推荐时,将SUBR作为数据增强技术构建混合训练集,对LLMs进行指令调整,防止过拟合,增强模型稳健性和泛化能力。
-
实验
- 实验设置:选用三个真实数据集,以AUC、Log Loss和ACC为评估指标,对比传统CTR模型和基于LM的模型,以Vicuna - 13B为基础LLM,采用8位量化和LoRA进行微调。
- 整体性能:零样本推荐中,ReLLa在多数指标上优于Vicuna - 13B;少样本推荐时,ReLLa性能显著优于多数基线模型,展现出优越的数据效率。
- 顺序行为理解:随着用户行为序列长度增加,ReLLa能缓解LLMs理解问题,AUC性能持续提升,而Vicuna - 13B性能会下降。
- 数据效率:少样本设置下,ReLLa数据效率高,相同样本数时性能远超SIM,样本极少时优势更明显。
- 消融研究:去除ReLLa组件实验表明,数据混合策略和模式丰富化对性能提升重要,模式丰富化作用更关键,SUBR可提高数据样本质量。
- 案例研究:通过可视化注意力分数发现,ReLLa的SUBR和ReiT能帮助LLM更好理解用户行为序列,关注相关历史项目。
-
相关工作:传统CTR预测模型分为基于特征交互和顺序推荐模型;语言模型在推荐系统中的应用包括特征工程、特征编码和评分/排名功能,本文聚焦于LLMs作为评分/排名功能的应用。
-
结论:识别并阐述了LLMs在推荐任务中对长用户行为序列理解不足的问题,提出ReLLa框架有效解决该问题。实验证明ReLLa性能优异,数据效率高,能更好理解长用户行为序列。