[2404.14294] A Survey on Efficient Inference for Large Language Models
一段话总结:本文是关于大语言模型高效推理的综述,分析了LLM推理效率低的原因,如模型大、注意力操作复杂度高和自回归解码方式等。提出从数据级、模型级和系统级进行优化的分类方法,并详细阐述各层级的优化技术,对代表性方法进行对比实验,最后讨论关键应用场景并指出未来研究方向,为LLM高效推理的研究和实践提供全面参考。
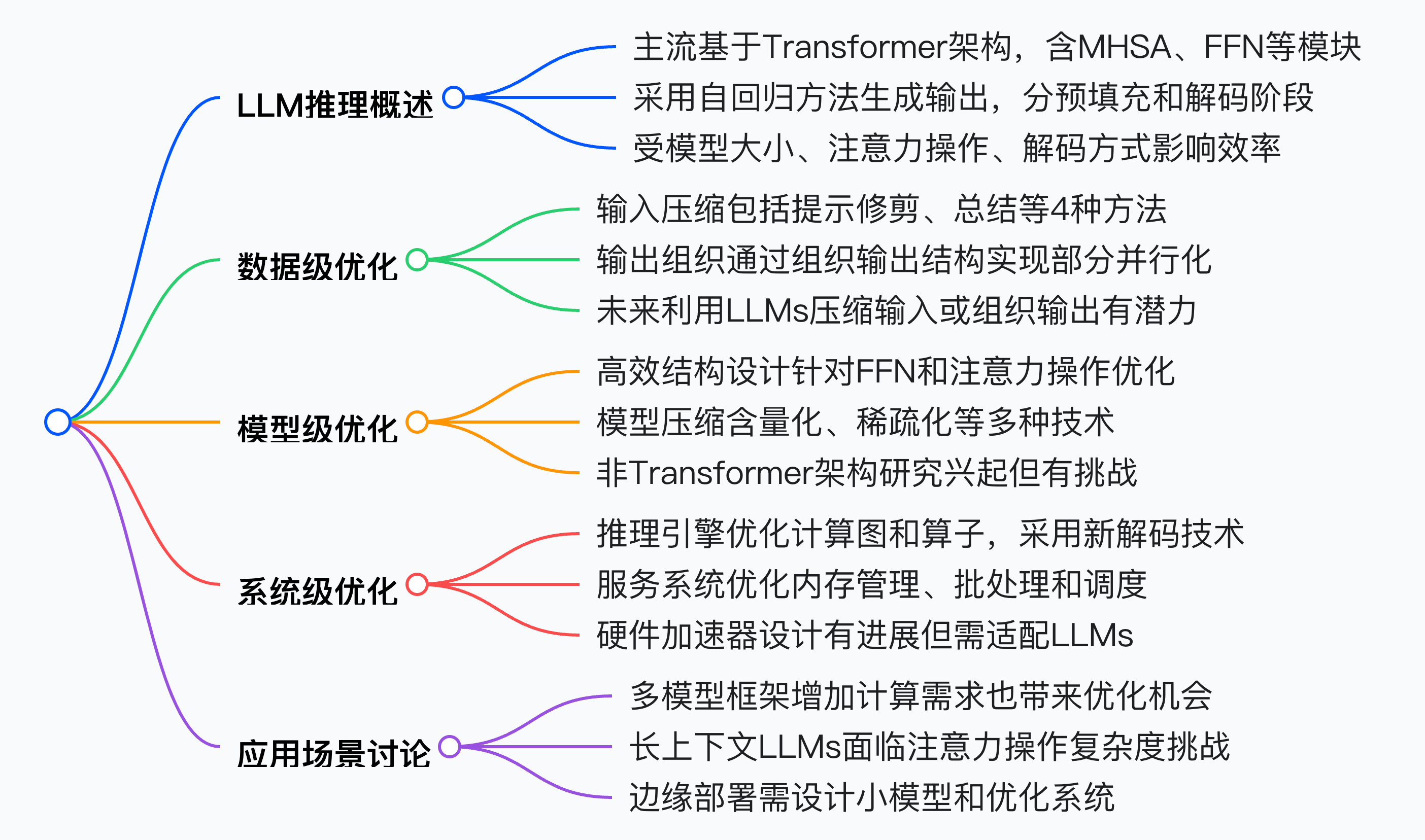
详细总结:
大语言模型(LLMs)近年来发展迅速,但推理时的高计算和内存需求限制了其在资源受限场景的部署。本文对LLM高效推理的研究进行综述,提出从数据级、模型级和系统级进行优化的分类方法,并探讨未来研究方向。
-
LLMs基础与效率瓶颈
- Transformer架构:主流LLMs基于Transformer架构,由Transformer块堆叠而成,核心为自注意力机制,用于捕捉长距离依赖和复杂关系。
- 推理过程:采用自回归方法生成输出,分预填充和解码阶段,关键技术为KV缓存,可加速生成过程。
- 效率瓶颈:模型规模大,如LLaMA-70B有700亿参数,增加计算和内存成本;注意力操作的二次计算复杂度,随输入长度增加成本剧增;自回归解码方式导致高内存访问成本和不规则内存访问模式。
-
数据级优化
- 输入压缩:通过缩短输入提示减少推理成本,包括提示修剪、提示总结、基于软提示的压缩和检索增强生成等方法。
- 输出组织:通过组织输出结构实现部分并行化,如Skeleton-of-Thought(SoT)、SGD、APAR和SGLang等技术,可提高硬件利用率和减少生成延迟。
-
模型级优化
- 高效结构设计:针对Transformer架构的FFN和注意力操作的效率问题,研究分为高效FFN设计、高效注意力设计和Transformer替代方案三类。
- 模型压缩:通过修改数据表示或架构提高推理效率,包括量化、稀疏化、结构优化、知识蒸馏和动态推理等技术。
-
系统级优化
- 推理引擎:优化计算图和算子,采用如FlashAttention等技术加速模型前向过程,引入推测解码技术提高解码效率,通过卸载技术缓解内存压力。
- 服务系统:优化内存管理、批处理和调度策略,提高系统吞吐量,分布式系统利用分布式特性优化推理服务。
-
关键应用场景讨论
- 多模型框架:提高了任务处理能力,但也增加了计算需求,同时为数据级和系统级优化创造了机会。
- 长上下文LLMs:面临注意力操作复杂度的挑战,需要探索新架构和确定合适的上下文长度。
- 边缘部署:在资源受限的边缘设备上部署LLMs仍有挑战,需设计高效小模型并优化系统。
-
未来研究方向
- 探索非Transformer架构的潜力和不足,研究其与注意力操作的融合。
- 改进模型压缩技术,减少对LLMs新兴能力的影响。
- 优化系统级调度策略,考虑实际服务系统中的多种目标。
| 优化层级 | 具体技术 | 主要方法 |
|---|---|---|
| 数据级优化 | 输入压缩 | 提示修剪、提示总结、基于软提示的压缩、检索增强生成 |
| 输出组织 | SoT、SGD、APAR、SGLang | |
| 模型级优化 | 高效结构设计 | 高效FFN设计、高效注意力设计、Transformer替代方案 |
| 模型压缩 | 量化、稀疏化、结构优化、知识蒸馏、动态推理 | |
| 系统级优化 | 推理引擎 | 图和算子优化、推测解码、卸载 |
| 服务系统 | 内存管理、连续批处理、调度策略、分布式系统 |
关键问题:
-
数据级优化中输入压缩和输出组织的主要作用分别是什么?
- 输入压缩主要作用是通过缩短模型输入,减少在预填充阶段因注意力操作带来的计算和内存成本,对于基于API的LLMs,还能降低输入令牌的API成本。输出组织的主要作用是通过组织输出内容的结构,实现部分并行化生成,缓解自回归解码方式带来的高内存访问成本,提高硬件利用率,减少生成延迟。
-
模型级优化中的量化技术如何分类,各有什么特点?
- 量化技术分为后训练量化(PTQ)和量化感知训练(QAT)。PTQ是对预训练模型进行量化,无需重新训练,但由于LLMs权重和激活的复杂性,直接应用传统量化技术有挑战。PTQ中不同研究在量化张量类型、数据格式、量化参数确定方案和量化值更新等方面存在差异。QAT是在模型训练过程中考虑量化影响,通过整合模拟量化效果的层,使权重适应量化误差,提升任务性能,但训练LLMs需要大量数据和计算资源,当前研究致力于减少其数据和计算需求。
-
系统级优化中的推理引擎优化包括哪些方面?
- 推理引擎优化包括图和算子优化、推测解码和卸载三个方面。图和算子优化通过对注意力算子和线性算子的优化,以及内核融合技术,减少运行时间;推测解码利用较小的草稿模型预测后续令牌,经目标LLM验证,提高解码效率;卸载是将部分存储从GPU转移到CPU,以应对LLMs的高内存需求,如FlexGen、llama.cpp等工作。