Token Merge 加速Diffusion模型推理 | OpenMMLab MMagic实现
ToMe:我的方法无需训练即可加速 ViT 模型|搞懂Transformer系列
论文总结
《TOKEN MERGING: YOUR VIT BUT FASTER》 作者为Daniel Bolya等人,来自Georgia Tech和Meta AI。
研究背景:
- 视觉Transformer(ViTs)在计算机视觉领域发展迅速,但存在运行大规模模型困难的问题。
- 最近出现了通过在运行时修剪标记来使模型更快的有前途的子领域,但标记修剪存在一些缺点。
主要贡献:
- 提出Token Merging方法:通过合并相似的标记来增加ViT模型的吞吐量,且该方法在训练和推理时都能使用,训练时能提高训练速度,减少精度下降。
- 进行广泛实验:在图像、视频和音频上进行实验,证明ToMe在所有情况下都具有竞争力,且能将物体部分合并为一个标记,在视频中能对物体进行跟踪。
相关工作:
- Efficient Transformers:一些工作试图在自然语言处理和视觉领域创建更高效的transformers,本文专注于通过合并标记来加速现有ViT模型。
- Token Reduction:最近有一些工作试图从transformers中修剪标记,但这些方法需要训练,且大多是动态的,不利于批处理推理或训练。
- Combining Tokens:很少有工作合并标记,且之前的方法在速度 - 精度权衡方面不太理想。
方法介绍:
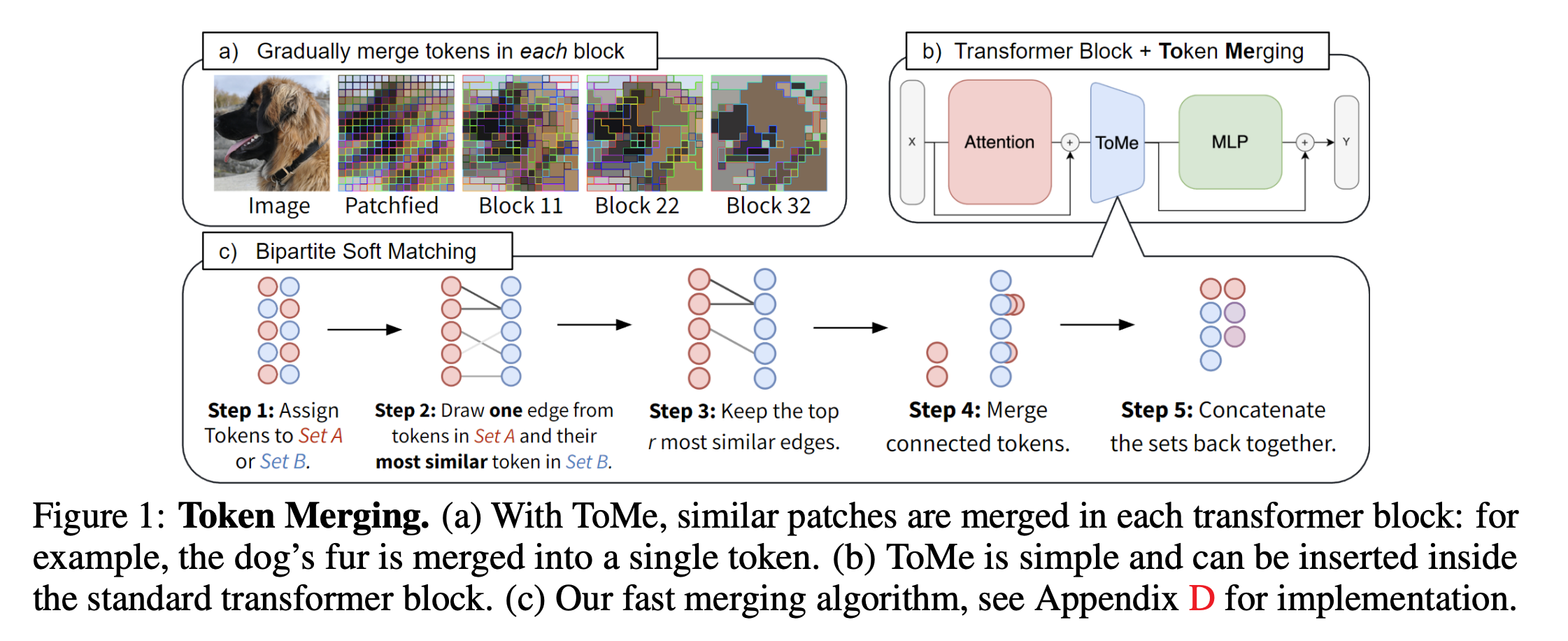
- 策略:在transformer的每个块中,逐渐合并标记以减少每层的标记数量r,且与图像内容无关。
- Token Similarity:使用QKV自注意力中的键(K)来确定标记的相似性,通过点积相似性度量(如余弦相似性)来判断包含相似信息的标记。
- Bipartite Soft Matching:提出一种更高效的匹配算法,通过将标记划分为两个大致相等的集合A和B,进行匹配和合并,该算法避免了迭代,且运行时间可忽略不计。
- Tracking Token Size:使用比例注意力(proportional attention)来解决合并后标记不再代表一个输入补丁的问题,同时在聚合标记时需要根据标记大小进行加权。
- Training with Merging:训练时将标记合并视为池化操作进行反向传播,不需要使用梯度技巧,且发现使用训练ViT的相同设置也是最优的。
图像实验:
- 设计选择:通过消融实验确定了默认的参数设置,包括使用注意力键(K)、余弦相似性、平均加权的标记合并方式、交替分配标记的分区方式以及使用比例注意力(除了现成的MAE模型)。
- 模型扫描:将标记合并方法应用于11个最先进的ViT模型,发现常数合并计划能使吞吐量提高2倍,且大型模型的精度下降较小。
- 与其他工作比较:与其他最先进的模型和标记修剪方法进行比较,发现ToMe能提高ViT模型的吞吐量,使其在速度上与低层级模型相当,且精度下降较小。
视频实验:
- 框架与结果:将标记合并方法应用于视频分类任务,使用Spatio - temporal MAE在Kinetics - 400上进行实验,结果表明ToMe能提高视频的吞吐量和精度,且在不同的合并计划下表现良好。
- 可视化:通过可视化展示了ToMe在视频中对物体的跟踪能力,能够将同一物体或部分在多个帧中合并为一个标记。
音频实验:
- 实验设置与结果:在音频MAE上进行实验,使用Huang等人的ViT - B模型在AudioSet - 2M上进行评估,结果表明ToMe能使基线的吞吐量翻倍,且mAP下降仅0.4%。
结论:
Token Merging(ToMe)能自然地利用输入的冗余性,在图像、视频和音频等领域获得了与最先进技术相竞争的速度和精度,可以被视为一种“自然”的分层模型,有望用于创建更好、更高效的transformers。
Bipartite Soft Matching逻辑
Bipartite Soft Matching是一种用于Token Merging的算法,其核心步骤如下:
- 分割Tokens:将输入模块的所有tokens均分为两个集合A和B,通常偶数索引为A,奇数索引为B。
- 计算相似度:对集合A中的每个token,计算其与集合B中每个token的相似度,并建立边。
- 选择最相似的边:保留最相似的r条边,其余边被丢弃。
- 融合Tokens:将仍然相连的tokens融合,通常通过取均值的方式。
- 输出结果:输出两个集合的并集,作为Token Merging的结果。
PyTorch实现代码
以下是Bipartite Soft Matching的PyTorch实现代码:
import torch
from typing import Tuple, Callable
def bipartite_soft_matching(
metric: torch.Tensor,
r: int,
class_token: bool = False,
distill_token: bool = False,
) -> Tuple[Callable, Callable]:
"""
Applies ToMe with a balanced matching set (50%, 50%).
Input size is [batch, tokens, channels].
r indicates the number of tokens to remove (max 50% of tokens).
Extra args:
- class_token: Whether or not there's a class token.
- distill_token: Whether or not there's also a distillation token.
When enabled, the class token and distillation tokens won't get merged.
"""
protected = 0
if class_token:
protected += 1
if distill_token:
protected += 1
# We can only reduce by a maximum of 50% tokens
t = metric.shape[1]
r = min(r, (t - protected) // 2)
if r <= 0:
return lambda x: x, lambda x: x
with torch.no_grad():
metric = metric / metric.norm(dim=-1, keepdim=True)
a, b = metric[..., ::2, :], metric[..., 1::2, :]
scores = a @ b.transpose(-1, -2)
if class_token:
scores[..., 0, :] = -float('inf')
if distill_token:
scores[..., :, 0] = -float('inf')
node_max, node_idx = scores.max(dim=-1)
edge_idx = node_max.argsort(dim=-1, descending=True)[..., None]
unm_idx = edge_idx[..., r:, :] # Unmerged Tokens
src_idx = edge_idx[..., :r, :] # Merged Tokens
dst_idx = node_idx[..., None].gather(dim=-2, index=src_idx)
def merge(x: torch.Tensor, mode="mean") -> torch.Tensor:
src, dst = x[..., ::2, :], x[..., 1::2, :]
n, t1, c = src.shape
unm = src.gather(dim=-2, index=unm_idx.expand(n, t1 - r, c))
src = src.gather(dim=-2, index=src_idx.expand(n, r, c))
dst = dst.scatter_reduce(-2, dst_idx.expand(n, r, c), src, reduce=mode)
if distill_token:
return torch.cat([unm[:, :1], dst[:, :1], unm[:, 1:], dst[:, 1:]], dim=1)
else:
return torch.cat([unm, dst], dim=1)
def unmerge(x: torch.Tensor) -> torch.Tensor:
unm_len = unm_idx.shape[1]
unm, dst = x[..., :unm_len, :], x[..., unm_len:, :]
n, _, c = unm.shape
src = dst.gather(dim=-2, index=dst_idx.expand(n, r, c))
out = torch.zeros(n, metric.shape[1], c, device=x.device, dtype=x.dtype)
out[..., 1::2, :] = dst
out.scatter_(dim=-2, index=(2 * unm_idx).expand(n, unm_len, c), src=unm)
out.scatter_(dim=-2, index=(2 * src_idx).expand(n, r, c), src=src)
return out
return merge, unmerge这段代码实现了Bipartite Soft Matching算法,其中包括了合并和未合并tokens的处理逻辑。希望这能帮助您理解并实现Token Merging中的Bipartite Soft Matching。