[2001.04451] Reformer: The Efficient Transformer
“Reformer: The Efficient Transformer”由Nikita Kitaev、Łukasz Kaiser、Anselm Levskaya撰写。文章提出Reformer模型,通过局部敏感哈希注意力机制和可逆残差层等技术,解决了Transformer模型训练成本高、内存消耗大的问题,在保持性能的同时,提高了处理长序列的效率。
-
研究背景:Transformer在多任务表现出色,但训练成本高昂。随着模型规模和序列长度增加,内存需求大幅上升,主要源于多层激活存储、中间层高维度计算以及注意力机制的二次方复杂度,限制了其在实际中的应用。
-
局部敏感哈希注意力机制(LSH Attention)
- 注意力机制基础:Transformer标准注意力采用缩放点积注意力,多头部注意力通过线性投影提升效果,但计算的内存和计算复杂度为 ,限制了长序列处理。
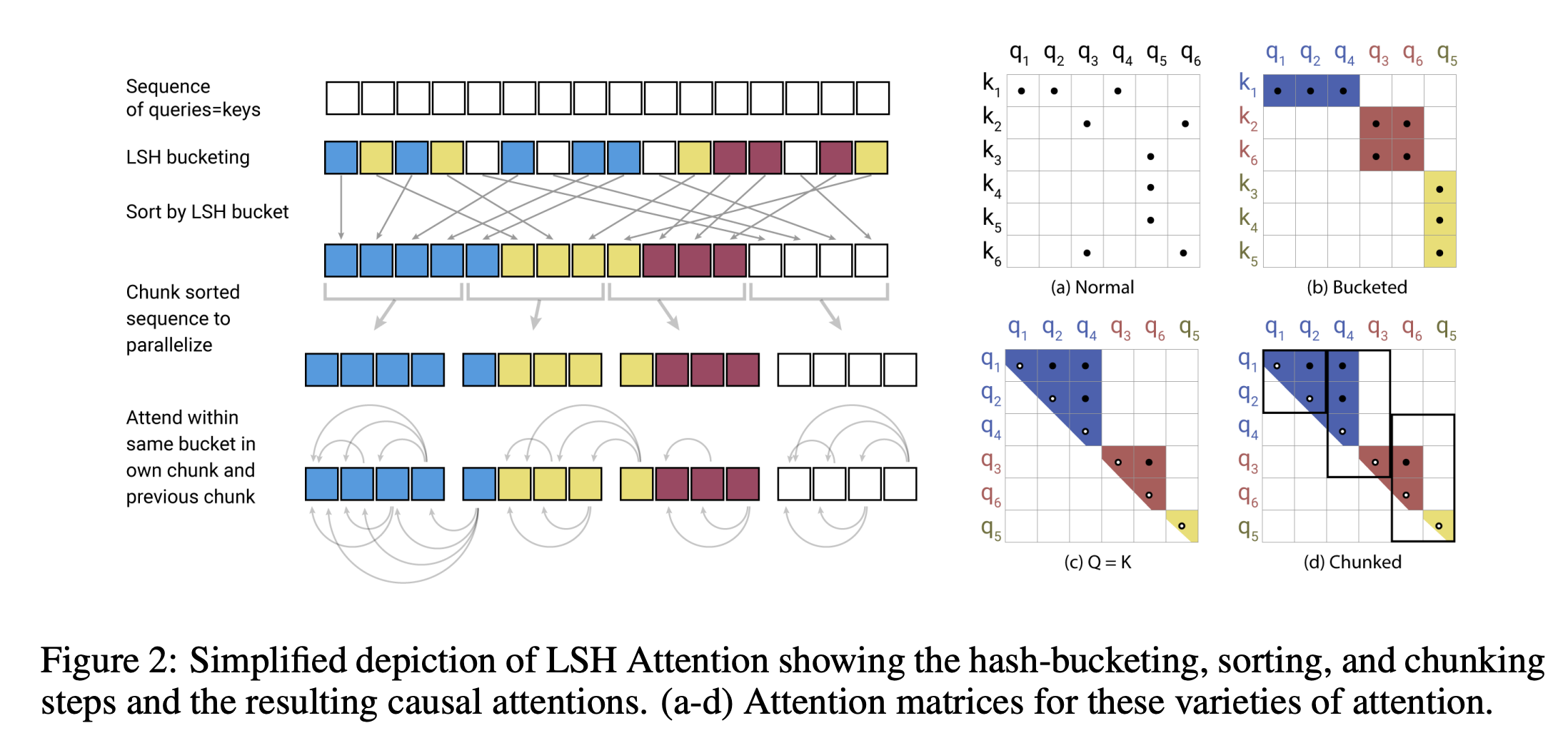
- LSH注意力原理:利用局部敏感哈希,为每个向量分配哈希值,使相近向量大概率落入同一哈希桶。通过随机投影实现LSH,将注意力计算限制在同一哈希桶内,降低复杂度至 。对哈希桶进行排序和分块,解决桶大小不均和批处理问题。
- 多轮LSH注意力:多次哈希可降低相似项落入不同桶的概率,多轮LSH注意力并行执行多次LSH注意力计算,合并结果。
- 因果掩码与共享QK:在Transformer解码器中,对共享QK注意力实施因果掩码,防止位置关注未来,并修改掩码避免令牌关注自身(特殊情况除外)。
- 合成任务分析:在复制序列的合成任务中,实验表明LSH注意力模型在训练和评估时,增加哈希轮数可提升准确率,训练时4哈希模型效果接近全注意力模型,评估时8哈希模型准确率更高。
-
可逆Transformer(Reversible Transformer)
- RevNets原理:可逆残差网络可从后续层激活恢复当前层激活,反向传播时无需存储中间值,降低内存需求。
- 可逆Transformer结构:将RevNet思想应用于Transformer,整合注意力和前馈层,将层归一化移至残差块内,避免存储每层激活,去除内存复杂度中的层数因子。
- 分块技术(Chunking):前馈层计算在序列位置间相互独立,可分块计算,降低内存使用。输出层对数概率也可分块计算损失。
- 内存优化策略:结合分块和可逆层,网络激活内存使用与层数无关。通过在非计算时将层参数在CPU和GPU间交换,解决参数随层数增加的内存问题。
-
相关工作:Transformer应用广泛,为降低其计算需求,已有精度降低、梯度检查点、稀疏注意力机制等方法。LSH此前未直接应用于Transformer注意力层,虽有相关外部内存研究,但与本文应用场景和方式不同。
-
实验
- 实验设置:在imagenet64、enwik8 - 64K任务和WMT 2014英德翻译任务上实验,使用3层模型,设置 , , ,总批次大小为8,用Adafactor优化器训练,代码开源。
- 实验结果:共享QK注意力不影响性能,enwik8任务中训练更快;可逆层节省内存且不降低准确率,在机器翻译任务中表现与传统Transformer相当;LSH注意力随哈希轮数增加精度提高,8轮时接近全注意力,且计算速度不随序列长度增加而变慢;大Reformer模型可在单核心训练,20层模型在enwik8和imagenet64任务上效果良好。
-
结论:Reformer结合Transformer建模能力,在长序列处理上高效且内存占用少,有助于大规模Transformer模型更广泛应用,为多领域生成任务开辟道路,如时间序列预测、音乐和图像视频生成等。