论文结构
- 研究背景与问题
- 推荐算法现状与问题
- LLMs在推荐系统中的应用及挑战
- 未解决问题探讨
- 分层大语言模型(HLLM)
- 架构设计
- 项目LLM与用户LLM
- 特殊标记与特征提取
- 训练目标
- 生成式推荐损失
- 判别式推荐损失与变体
- 架构设计
- 实验设置与结果
- 数据集与评估指标
- 实验结果分析
- 预训练与微调影响
- 模型扩展性验证
- 与SOTA方法对比
- 训练与服务效率评估
- 结论与贡献
- 研究成果总结
- 模型优势与局限性
- 未来研究方向
论文总结
“HLLM: Enhancing Sequential Recommendations via Hierarchical Large Language Models for Item and User Modeling”由Junyi Chen、Lu Chi等人撰写,提出了分层大语言模型(HLLM)架构以改进顺序推荐系统,以下是详细总结:
-
研究背景与动机
- 现有推荐系统主流方法基于ID,存在依赖ID特征、神经网络较浅等问题。
- 大语言模型(LLMs)在各领域取得成功,但与推荐系统结合时面临挑战,如输入序列长、效率低、性能提升不显著等,且其预训练权重价值、微调必要性及在推荐系统中的可扩展性有待探索。
-
模型方法
- 问题表述:给定用户及其历史交互序列,预测下一个项目,本文仅使用项目文本信息。
-
分层大语言模型架构
- 项目LLM(Item LLM):在项目文本描述后添加特殊标记[ITEM],将其输入LLM,取[ITEM]对应的隐藏状态作为项目嵌入,用于提取项目特征。
-
用户LLM(User LLM):将用户历史交互项目通过Item LLM转换为特征序列,输入User LLM预测下一个项目嵌入。User LLM输入和输出均为项目嵌入,丢弃预训练LLM的词嵌入但保留其他权重。
- 训练目标
-
生成式推荐:采用下一项预测作为训练目标,使用InfoNCE损失,预测用户历史中前一项嵌入的下一项嵌入。
- 判别式推荐:判断用户对目标项目是否感兴趣,有早期融合和晚期融合两种变体,可将生成式推荐的下一项预测作为辅助损失增强性能。
-
实验过程与结果
-
实验设置
- 数据集和评估指标:使用PixelRec和Amazon Book Reviews数据集,采用留一法划分数据,用Recall@K(R@K)和NDCG@K(N@K)评估。
-
基线模型和训练:基线模型为SASRec和HSTU,HLLM - 1B使用TinyLlama - 1.1B,HLLM - 7B使用Baichuan2 - 7B,训练时对参数设置和训练轮数等进行调整。
- 预训练和微调(RQ1)
-
预训练权重对HLLM有益,预训练令牌数量与性能正相关,但在对话数据上的监督微调(SFT)可能有轻微负面影响。同时,对Item LLM和User LLM进行微调对超越基于ID的模型至关重要。
- 模型缩放(RQ2)
-
Item LLM和User LLM参数数量增加均能提升性能,在Amazon Books数据集上缩放至70亿参数时性能进一步提高,且在不同数据量下HLLM表现出良好扩展性,无性能瓶颈。
- 与SOTA方法比较(RQ3)
-
HLLM在所有数据集的各项指标上均显著优于其他模型,如在Pixel8M和Amazon Books数据集上,HLLM - 1B相比基线模型有明显提升,HLLM - 7B提升更显著,而基于ID的模型提升相对较小。
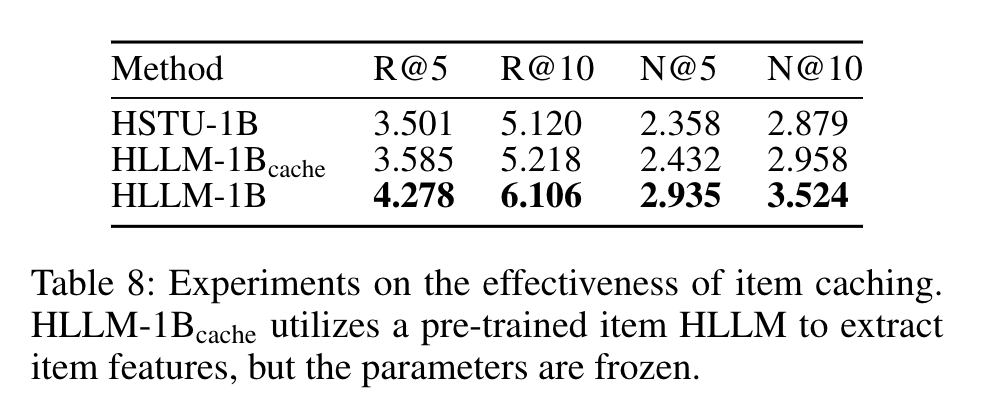
- 训练和服务效率(RQ4)
-
HLLM训练数据效率高于基于ID的模型,通过缓存项目嵌入可降低计算复杂度,在工业场景中训练和服务成本可与ID - 基于模型匹配,如在Pixel8M数据集上的实验证明了项目缓存的有效性。
- 在线A/B测试
-
HLLM在工业实践中采用判别式推荐的晚期融合变体,训练分三个阶段,最终在在线A/B测试中关键指标显著提升。
-
-
研究结论
- HLLM架构利用LLMs提取项目特征和建模用户兴趣,有效整合预训练知识,微调对推荐任务至关重要,具有良好扩展性。
- 实验表明HLLM优于传统基于ID的模型,在学术数据集上取得领先成果,在线A/B测试验证了其实用性,推动了推荐系统领域发展。
Table 1: Statics of PixelRec and Amazon Book Reviews
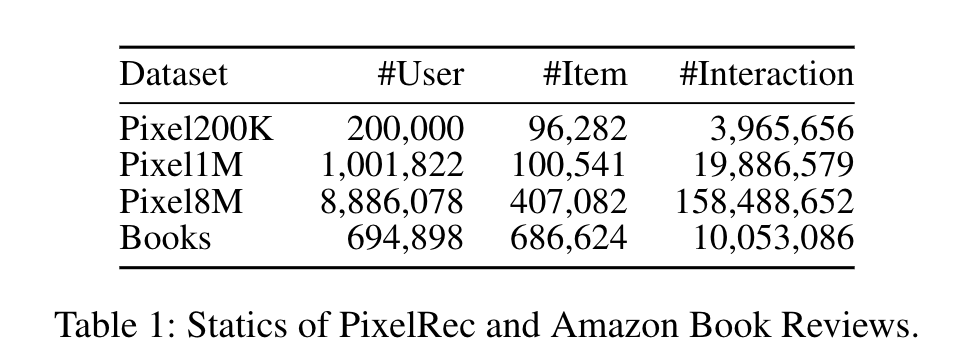
Table 2: Ablation studies of pre-training on Pixel200K with HLLM-1B
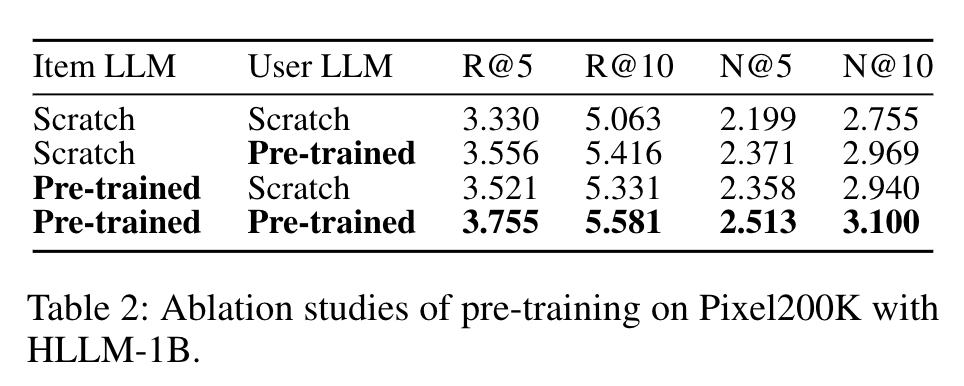
Table 3: The impact of different pre-training token counts
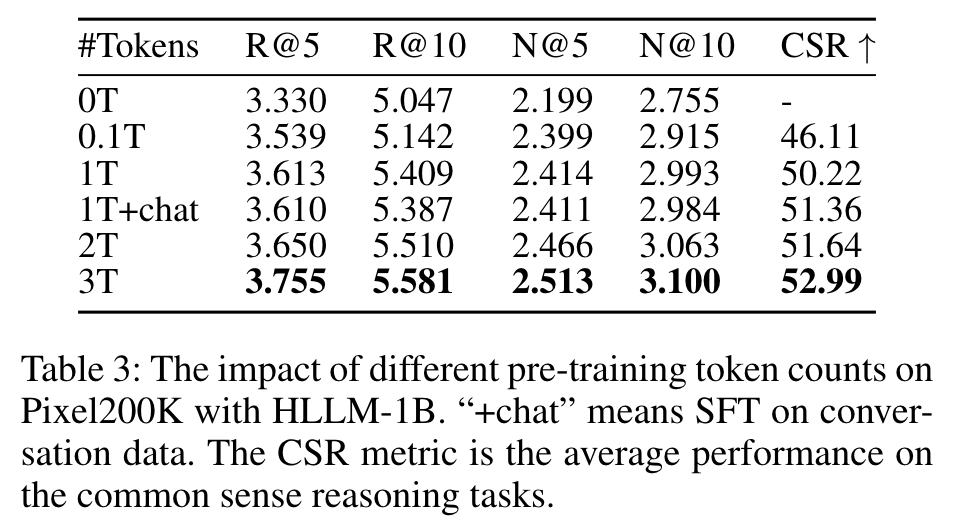
Table 4: Ablation studies of fine-tuning on Pixel200K with HLLM-1B
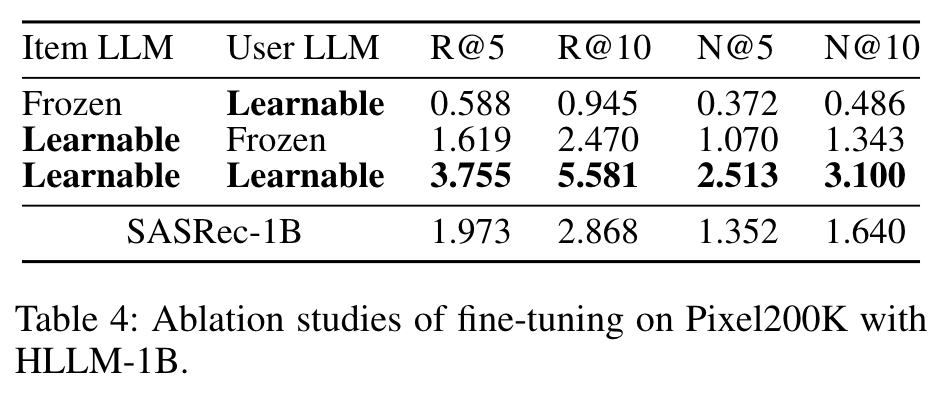
Table 5: Experiments with different sizes of the item model
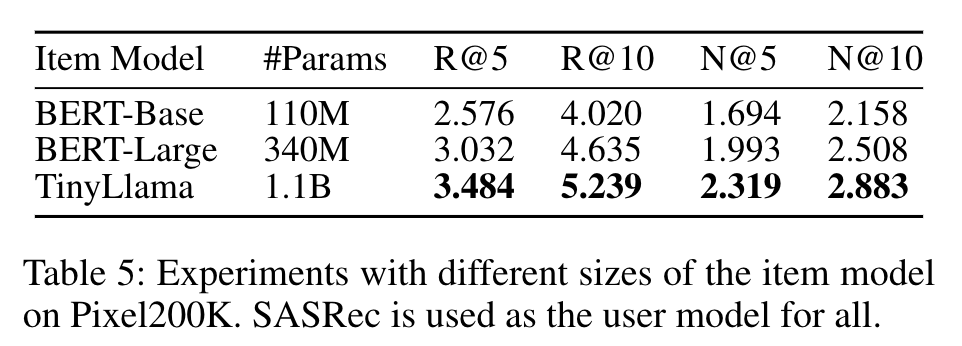
Table 6: Experiments with different sizes of the user model
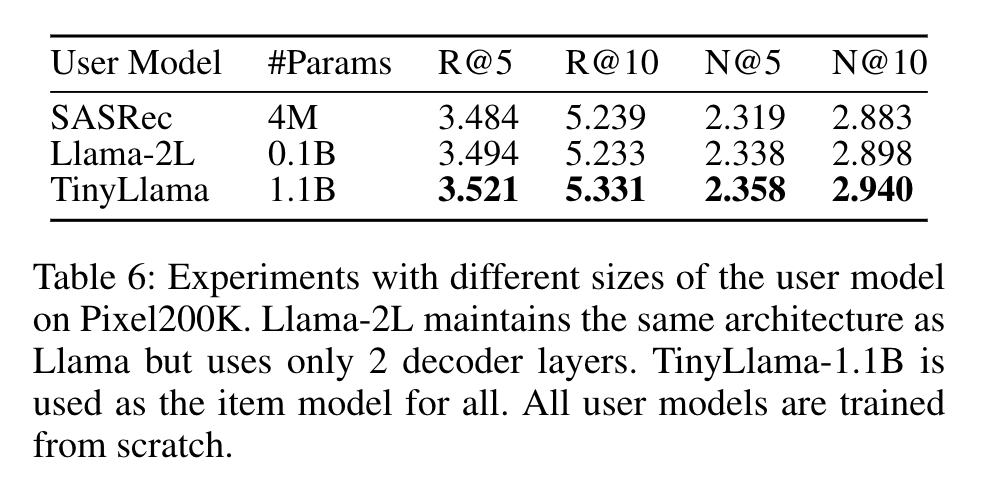
Table 7: Performance comparison of HLLM with SOTA models
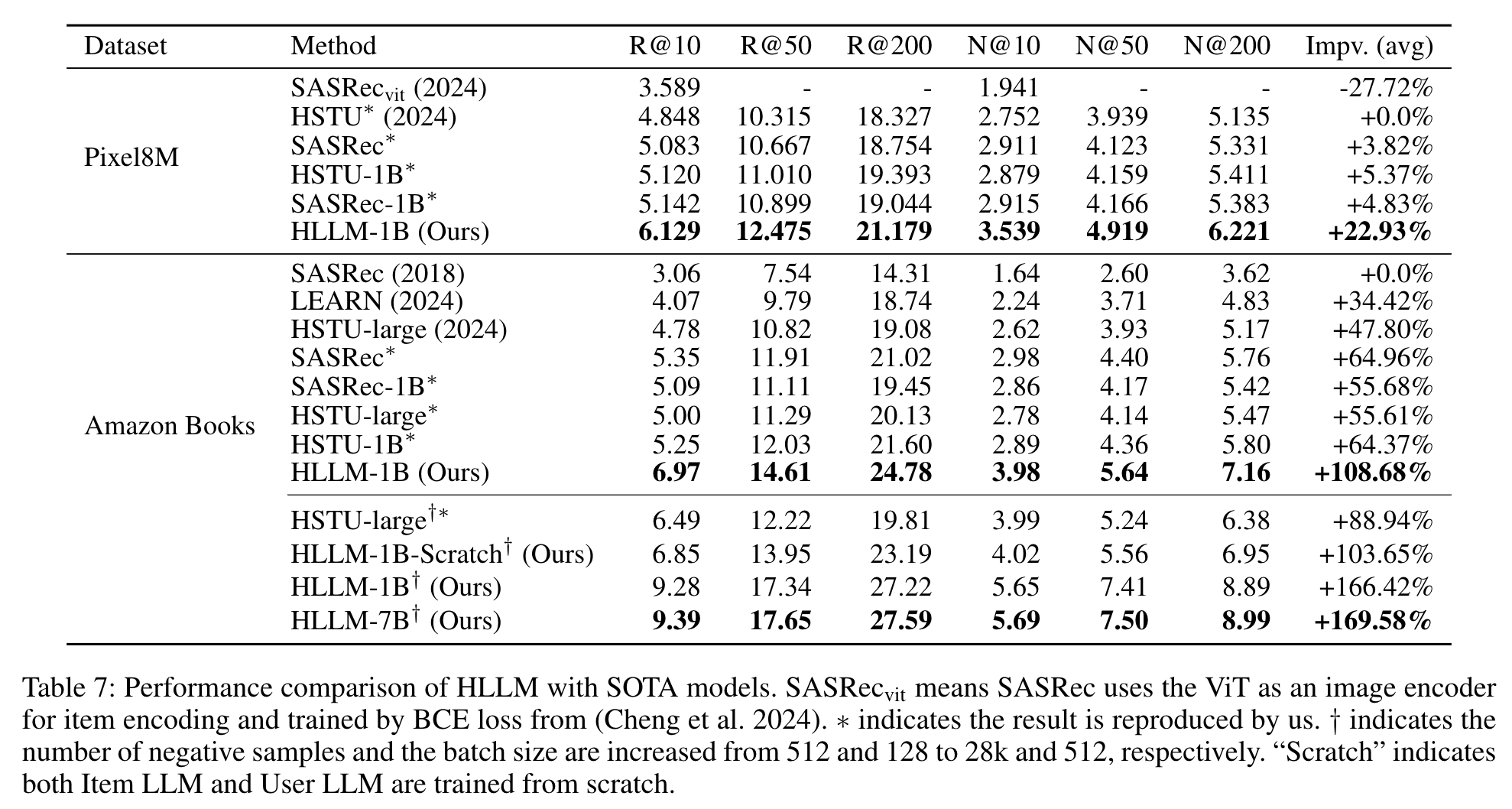
Table 8: Experiments on the effectiveness of item caching
时间戳处理伪代码
