CONTENTS
Model structure
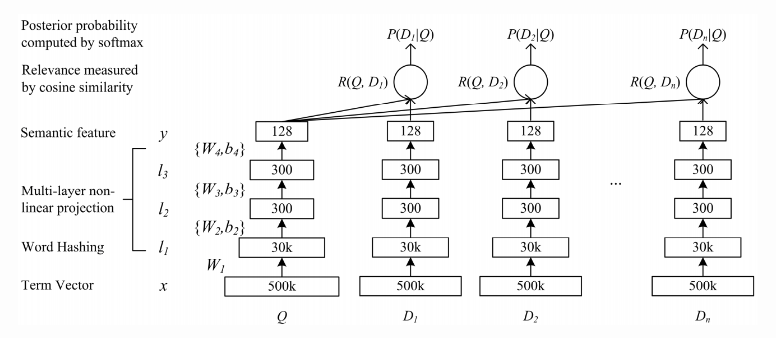
Input Layer
the term vector with 500K words can be mapped to n-gram vectors sized only aroudn 30K.
A typical query/doc input is shown below as pairs of N:X, saying the Nth n-gram appears X times in the query/doc.
46238:1 24108:1 24016:1 5618:1 8818:1
Hidden Layer
There are 3 fully connected (FC) layers in the network, with 300, 300, 128 neurons in each layer. Each input x is projected linearly by Wx+b and then activated non-linearly with tanh/relu functions to generate input for the next layer.
Output Layer
The output of the FC layers is a 128-length vector and fed to calculate cosine similarities.
Implementation
Input
To fully utilize the GPU capability, we feed the model with Q and D in batches of size BS. The original input vector [TRIGRAM_D] is now a matrix with size shaped [BS, TRIGRAM_D]. TRIGRAM_D is the total number of trigrams appear in all queries and documents.
Another problem is that the input matrix is very sparse. We find that 80% of the queries can be composed of less than 30 trigrams, which makes most of the input matrix values zero.
Tensorflow supports sparse placeholders, which are used to hold the input tensors:
query_batch = tf.sparse_placeholder(tf.float32,
shape=[None,TRIGRAM_D],
name='QueryBatch')
doc_batch = tf.sparse_placeholder(tf.float32,
shape=[None, TRIGRAM_D],
name='DocBatch')Initialize
Weights and biases are initialized in the uniform distribution as decribed in the paper. here only layer 1 is presented.
# L1_N = 300
l1_par_range = np.sqrt(6.0 / (TRIGRAM_D + L1_N))
weight1 = tf.Variable(tf.random_uniform([TRIGRAM_D, L1_N],
-l1_par_range,
l1_par_range))
bias1 = tf.Variable(tf.random_uniform([L1_N],
-l1_par_range,
l1_par_range))FC Layer
query_l1 = tf.sparse_tensor_dense_matmul(query_batch, weight1) + bias1
doc_l1 = tf.sparse_tensor_dense_matmul(doc_batch, weight1) + bias1
query_l1_out = tf.nn.relu(query_l1)
doc_l1_out = tf.nn.relu(doc_l1)Cosine Similarity
# NEG is the number of negative documents
query_norm = tf.tile(tf.sqrt(tf.reduce_sum(tf.square(query_y), 1, True)),
[NEG + 1, 1])
doc_norm = tf.sqrt(tf.reduce_sum(tf.square(doc_y), 1, True))
prod = tf.reduce_sum(tf.mul(tf.tile(query_y, [NEG + 1, 1]), doc_y), 1, True)
norm_prod = tf.mul(query_norm, doc_norm)
cos_sim_raw = tf.truediv(prod, norm_prod)
cos_sim = tf.transpose(tf.reshape(tf.transpose(cos_sim_raw), [NEG + 1, BS])) * GammaLoss
prob = tf.nn.softmax((cos_sim))
hit_prob = tf.slice(prob, [0, 0], [-1, 1])
loss = -tf.reduce_sum(tf.log(hit_prob)) / BSTrain
train_step = tf.train.GradientDescentOptimizer(FLAGS.learning_rate).minimize(loss)Run
Running Tensorflow with a session:
# Allow GPU to allocate memory dynamically
# instead of taking all memory at once in
# the beginning
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
with tf.Session(config=config) as sess:
sess.run(tf.initialize_all_variables())
for step in range(FLAGS.max_steps):
sess.run(train_step, feed_dict={query_batch : ...
doc_batch : ...}})Full Code
import pickle
import random
import time
import sys
import numpy as np
import tensorflow as tf
flags = tf.app.flags
FLAGS = flags.FLAGS
flags.DEFINE_string('summaries_dir', '/tmp/dssm-400-120-relu', 'Summaries directory')
flags.DEFINE_float('learning_rate', 0.1, 'Initial learning rate.')
flags.DEFINE_integer('max_steps', 900000, 'Number of steps to run trainer.')
flags.DEFINE_integer('epoch_steps', 18000, "Number of steps in one epoch.")
flags.DEFINE_integer('pack_size', 2000, "Number of batches in one pickle pack.")
flags.DEFINE_bool('gpu', 1, "Enable GPU or not")
start = time.time()
doc_train_data = None
query_train_data = None
# load test data for now
query_test_data = pickle.load(open('../data/query.test.1.pickle', 'rb')).tocsr()
doc_test_data = pickle.load(open('../data/doc.test.1.pickle', 'rb')).tocsr()
def load_train_data(pack_idx):
global doc_train_data, query_train_data
doc_train_data = None
query_train_data = None
start = time.time()
doc_train_data = pickle.load(open('../data/doc.train.' + str(pack_idx)+ '.pickle', 'rb')).tocsr()
query_train_data = pickle.load(open('../data/query.train.'+ str(pack_idx)+ '.pickle', 'rb')).tocsr()
end = time.time()
print ("\nTrain data %d/9 is loaded in %.2fs" % (pack_idx, end - start))
end = time.time()
print("Loading data from HDD to memory: %.2fs" % (end - start))
TRIGRAM_D = 49284
NEG = 50
BS = 1000
L1_N = 400
L2_N = 120
query_in_shape = np.array([BS, TRIGRAM_D], np.int64)
doc_in_shape = np.array([BS, TRIGRAM_D], np.int64)
def variable_summaries(var, name):
"""Attach a lot of summaries to a Tensor."""
with tf.name_scope('summaries'):
mean = tf.reduce_mean(var)
tf.scalar_summary('mean/' + name, mean)
with tf.name_scope('stddev'):
stddev = tf.sqrt(tf.reduce_sum(tf.square(var - mean)))
tf.scalar_summary('sttdev/' + name, stddev)
tf.scalar_summary('max/' + name, tf.reduce_max(var))
tf.scalar_summary('min/' + name, tf.reduce_min(var))
tf.histogram_summary(name, var)
with tf.name_scope('input'):
# Shape [BS, TRIGRAM_D].
query_batch = tf.sparse_placeholder(tf.float32, shape=query_in_shape, name='QueryBatch')
# Shape [BS, TRIGRAM_D]
doc_batch = tf.sparse_placeholder(tf.float32, shape=doc_in_shape, name='DocBatch')
with tf.name_scope('L1'):
l1_par_range = np.sqrt(6.0 / (TRIGRAM_D + L1_N))
weight1 = tf.Variable(tf.random_uniform([TRIGRAM_D, L1_N], -l1_par_range, l1_par_range))
bias1 = tf.Variable(tf.random_uniform([L1_N], -l1_par_range, l1_par_range))
variable_summaries(weight1, 'L1_weights')
variable_summaries(bias1, 'L1_biases')
# query_l1 = tf.matmul(tf.to_float(query_batch),weight1)+bias1
query_l1 = tf.sparse_tensor_dense_matmul(query_batch, weight1) + bias1
# doc_l1 = tf.matmul(tf.to_float(doc_batch),weight1)+bias1
doc_l1 = tf.sparse_tensor_dense_matmul(doc_batch, weight1) + bias1
query_l1_out = tf.nn.relu(query_l1)
doc_l1_out = tf.nn.relu(doc_l1)
with tf.name_scope('L2'):
l2_par_range = np.sqrt(6.0 / (L1_N + L2_N))
weight2 = tf.Variable(tf.random_uniform([L1_N, L2_N], -l2_par_range, l2_par_range))
bias2 = tf.Variable(tf.random_uniform([L2_N], -l2_par_range, l2_par_range))
variable_summaries(weight2, 'L2_weights')
variable_summaries(bias2, 'L2_biases')
query_l2 = tf.matmul(query_l1_out, weight2) + bias2
doc_l2 = tf.matmul(doc_l1_out, weight2) + bias2
query_y = tf.nn.relu(query_l2)
doc_y = tf.nn.relu(doc_l2)
with tf.name_scope('FD_rotate'):
# Rotate FD+ to produce 50 FD-
temp = tf.tile(doc_y, [1, 1])
for i in range(NEG):
rand = int((random.random() + i) * BS / NEG)
doc_y = tf.concat(0,
[doc_y,
tf.slice(temp, [rand, 0], [BS - rand, -1]),
tf.slice(temp, [0, 0], [rand, -1])])
with tf.name_scope('Cosine_Similarity'):
# Cosine similarity
query_norm = tf.tile(tf.sqrt(tf.reduce_sum(tf.square(query_y), 1, True)), [NEG + 1, 1])
doc_norm = tf.sqrt(tf.reduce_sum(tf.square(doc_y), 1, True))
prod = tf.reduce_sum(tf.mul(tf.tile(query_y, [NEG + 1, 1]), doc_y), 1, True)
norm_prod = tf.mul(query_norm, doc_norm)
cos_sim_raw = tf.truediv(prod, norm_prod)
cos_sim = tf.transpose(tf.reshape(tf.transpose(cos_sim_raw), [NEG + 1, BS])) * 20
with tf.name_scope('Loss'):
# Train Loss
prob = tf.nn.softmax((cos_sim))
hit_prob = tf.slice(prob, [0, 0], [-1, 1])
loss = -tf.reduce_sum(tf.log(hit_prob)) / BS
tf.scalar_summary('loss', loss)
with tf.name_scope('Training'):
# Optimizer
train_step = tf.train.GradientDescentOptimizer(FLAGS.learning_rate).minimize(loss)
# with tf.name_scope('Accuracy'):
# correct_prediction = tf.equal(tf.argmax(prob, 1), 0)
# accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# tf.scalar_summary('accuracy', accuracy)
merged = tf.merge_all_summaries()
with tf.name_scope('Test'):
average_loss = tf.placeholder(tf.float32)
loss_summary = tf.scalar_summary('average_loss', average_loss)
def pull_batch(query_data, doc_data, batch_idx):
# start = time.time()
query_in = query_data[batch_idx * BS:(batch_idx + 1) * BS, :]
doc_in = doc_data[batch_idx * BS:(batch_idx + 1) * BS, :]
query_in = query_in.tocoo()
doc_in = doc_in.tocoo()
query_in = tf.SparseTensorValue(
np.transpose([np.array(query_in.row, dtype=np.int64), np.array(query_in.col, dtype=np.int64)]),
np.array(query_in.data, dtype=np.float),
np.array(query_in.shape, dtype=np.int64))
doc_in = tf.SparseTensorValue(
np.transpose([np.array(doc_in.row, dtype=np.int64), np.array(doc_in.col, dtype=np.int64)]),
np.array(doc_in.data, dtype=np.float),
np.array(doc_in.shape, dtype=np.int64))
# end = time.time()
# print("Pull_batch time: %f" % (end - start))
return query_in, doc_in
def feed_dict(Train, batch_idx):
"""Make a TensorFlow feed_dict: maps data onto Tensor placeholders."""
if Train:
query_in, doc_in = pull_batch(query_train_data, doc_train_data, batch_idx)
else:
query_in, doc_in = pull_batch(query_test_data, doc_test_data, batch_idx)
return {query_batch: query_in, doc_batch: doc_in}
config = tf.ConfigProto() # log_device_placement=True)
config.gpu_options.allow_growth = True
#if not FLAGS.gpu:
#config = tf.ConfigProto(device_count= {'GPU' : 0})
with tf.Session(config=config) as sess:
sess.run(tf.initialize_all_variables())
train_writer = tf.train.SummaryWriter(FLAGS.summaries_dir + '/train', sess.graph)
test_writer = tf.train.SummaryWriter(FLAGS.summaries_dir + '/test', sess.graph)
# Actual execution
start = time.time()
# fp_time = 0
# fbp_time = 0
for step in range(FLAGS.max_steps):
batch_idx = step % FLAGS.epoch_steps
if batch_idx % FLAGS.pack_size == 0:
load_train_data(batch_idx / FLAGS.pack_size + 1)
# # setup toolbar
# sys.stdout.write("[%s]" % (" " * toolbar_width))
# #sys.stdout.flush()
# sys.stdout.write("\b" * (toolbar_width + 1)) # return to start of line, after '['
if batch_idx % (FLAGS.pack_size / 64) == 0:
progress = 100.0 * batch_idx / FLAGS.epoch_steps
sys.stdout.write("\r%.2f%% Epoch" % progress)
sys.stdout.flush()
# t1 = time.time()
# sess.run(loss, feed_dict = feed_dict(True, batch_idx))
# t2 = time.time()
# fp_time += t2 - t1
# #print(t2-t1)
# t1 = time.time()
sess.run(train_step, feed_dict=feed_dict(True, batch_idx % FLAGS.pack_size))
# t2 = time.time()
# fbp_time += t2 - t1
# #print(t2 - t1)
# if batch_idx % 2000 == 1999:
# print ("MiniBatch: Average FP Time %f, Average FP+BP Time %f" %
# (fp_time / step, fbp_time / step))
if batch_idx == FLAGS.epoch_steps - 1:
end = time.time()
epoch_loss = 0
for i in range(FLAGS.pack_size):
loss_v = sess.run(loss, feed_dict=feed_dict(True, i))
epoch_loss += loss_v
epoch_loss /= FLAGS.pack_size
train_loss = sess.run(loss_summary, feed_dict={average_loss: epoch_loss})
train_writer.add_summary(train_loss, step + 1)
# print ("MiniBatch: Average FP Time %f, Average FP+BP Time %f" %
# (fp_time / step, fbp_time / step))
#
print ("\nEpoch #%-5d | Train Loss: %-4.3f | PureTrainTime: %-3.3fs" %
(step / FLAGS.epoch_steps, epoch_loss, end - start))
epoch_loss = 0
for i in range(FLAGS.pack_size):
loss_v = sess.run(loss, feed_dict=feed_dict(False, i))
epoch_loss += loss_v
epoch_loss /= FLAGS.pack_size
test_loss = sess.run(loss_summary, feed_dict={average_loss: epoch_loss})
test_writer.add_summary(test_loss, step + 1)
start = time.time()
print ("Epoch #%-5d | Test Loss: %-4.3f | Calc_LossTime: %-3.3fs" %
(step / FLAGS.epoch_steps, epoch_loss, start - end))