目录
简介
本文简单介绍如何使用keras训练word2vec,用的CBOW + Negative Sampling,原理请参考其他博客,不复杂。训练模型的结构图如下:
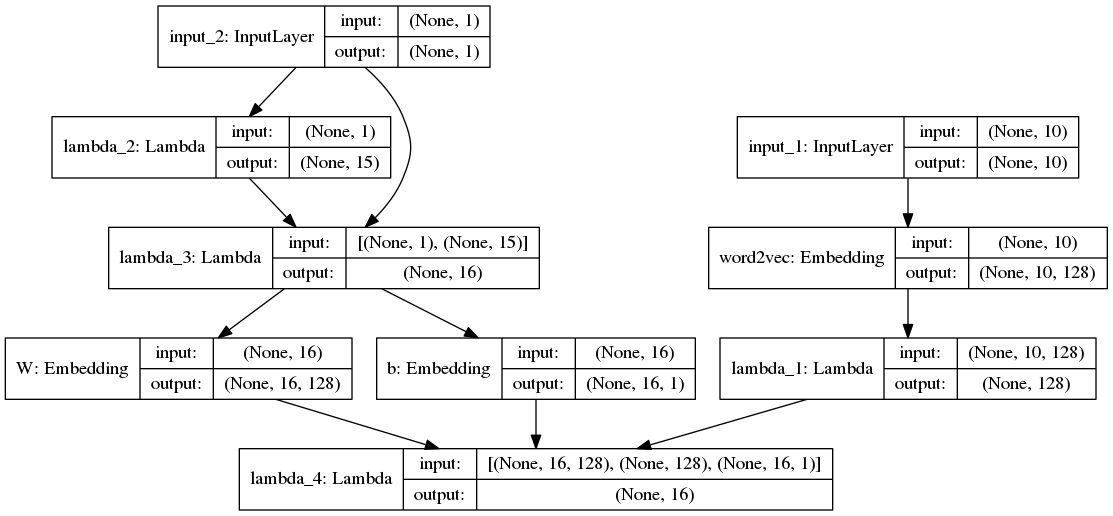
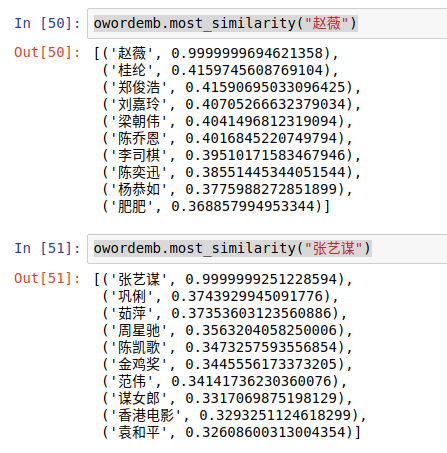
效果:
训练
训练代码如下,主要参数设置为:
- WINDOW_SIZE:窗口大小5
- SUB_SAMPLE_THRESHOLD: 负采样阈值1e-5
- EMBEDDING_SIZE: 词向量维度128
- NEGATIVE_NUMBER:负采样样本数15
- EPOCH_NUMBER: 训练集迭代次数20
# coding: utf8
import jieba
import numpy as np
from keras.layers import Input,Embedding,Lambda
from keras.models import Model
import keras.backend as K
import tensorflow as tf
import os
from keras.backend.tensorflow_backend import set_session
os.environ["CUDA_VISIBLE_DEVICES"] = "2"
config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.3
set_session(tf.Session(config=config))
class Sentences:
"""
句子
"""
def __init__(self, filename):
self.filename = filename
pass
def __iter__(self):
for line in open(self.filename):
splits = jieba.cut(line.strip(), cut_all=False)
splits = [term.encode("utf8", "ignore") for term in splits]
yield splits
class Word2vec:
def __init__(self, conf_dict, corpus_path, model_save_path):
self.MIN_WORD_FREQ_THRESHOLD = conf_dict.get("MIN_WORD_FREQ_THRESHOLD", 10)
self.WINDOW_SIZE = conf_dict.get("WINDOW_SIZE", 5)
self.SUB_SAMPLE_THRESHOLD = conf_dict.get("SUB_SAMPLE_THRESHOLD", 1e-5)
self.BATCH_SIZE = conf_dict.get("BATCH_SIZE", 20)
self.EMBEDDING_SIZE = conf_dict.get("EMBEDDING_SIZE", 128)
self.NEGATIVE_NUMBER = conf_dict.get("NEGATIVE_NUMBER", 15)
self.EPOCH_NUMBER = conf_dict.get("EPOCH_NUMBER", 2)
self.WORKER_NUMBER = conf_dict.get("WORKER_NUMBER", 4)
self.word_freq_map = dict()
self.id_word_map = dict()
self.word_id_map = dict()
self.word_number = 0
self.sentence_number = 0
self.sentences = Sentences(corpus_path)
self.sub_sample_map = dict()
self.model_save_path = model_save_path
self.normalized_embeddings = None
def process_corpus(self):
tmp_word_freq_map = dict()
for sentence in self.sentences:
self.sentence_number += 1
for word in sentence:
tmp_word_freq_map[word] = tmp_word_freq_map.get(word, 0) + 1
if self.sentence_number % 10000 == 0:
print("已经扫描了第%d篇文章" % self.sentence_number)
self.word_freq_map = {word:freq
for word, freq in tmp_word_freq_map.items()
if freq >= self.MIN_WORD_FREQ_THRESHOLD}
self.id_word_map = {index+1: word
for index, word in enumerate(self.word_freq_map.keys())}
self.id_word_map[0] = "UNK"
self.word_id_map = {word: index
for index, word in self.id_word_map.items()}
self.word_number = len(self.id_word_map.items())
sub_sample_threshold = self.word_number * self.SUB_SAMPLE_THRESHOLD
self.sub_sample_map = {word: (sub_sample_threshold / freq)
+ (sub_sample_threshold / freq) ** 0.5
for word, freq in self.word_freq_map.items()
if freq > sub_sample_threshold}
self.sub_sample_map = {self.word_id_map[word]: ratio
for word, ratio in self.sub_sample_map.items()
if ratio < 1.}
def get_batch_data(self):
# 17253/33333
# ValueError: Error when checking input: expected input_1 to have shape (10,) but got array with shape (1,)
while True:
context_words, target_word = list(), list()
batch_number = 0
for sentence in self.sentences:
sentence = [0] * self.WINDOW_SIZE \
+ [self.word_id_map[w] for w in sentence if w in self.word_id_map] \
+ [0] * self.WINDOW_SIZE
random_ratio = np.random.random(len(sentence))
has_result = False
for i in range(self.WINDOW_SIZE, len(sentence)-self.WINDOW_SIZE):
# 满足降采样条件的直接跳过
if sentence[i] in self.sub_sample_map and random_ratio[i] > self.sub_sample_map[sentence[i]]:
continue
tmp = sentence[i - self.WINDOW_SIZE:i] + sentence[i+1: i+1+self.WINDOW_SIZE]
if len(tmp) != self.WINDOW_SIZE * 2:
continue
has_result = True
context_words.append(tmp)
target_word.append(sentence[i])
if has_result:
batch_number += 1
if batch_number == self.BATCH_SIZE:
context_words, target_word = np.array(context_words), np.array(target_word)
z = np.zeros((len(context_words), 1))
yield [context_words, target_word], z
context_words, target_word = list(), list()
batch_number = 0
def get_cbow_model(self):
context_words_input = Input(shape=(self.WINDOW_SIZE * 2,), dtype='int32')
context_embedding_input = Embedding(self.word_number, self.EMBEDDING_SIZE, name='word2vec')(context_words_input)
context_sum_embedding_input = Lambda(lambda x: K.sum(x, axis=1))(context_embedding_input)
target_word_input = Input(shape=(1,), dtype='int32')
negatives_word_input = Lambda(lambda x:
K.random_uniform(
(K.shape(x)[0], self.NEGATIVE_NUMBER), 0, self.word_number, 'int32')
)(target_word_input)
candidate_words_input = Lambda(lambda x: K.concatenate(x))([target_word_input, negatives_word_input])
candidate_embedding_weights = Embedding(self.word_number, self.EMBEDDING_SIZE, name='W')(candidate_words_input)
candidate_embedding_biases = Embedding(self.word_number, 1, name='b')(candidate_words_input)
softmax = Lambda(lambda x: K.softmax((K.batch_dot(x[0], K.expand_dims(x[1], 2)) + x[2])[:, :, 0])
)([candidate_embedding_weights, context_sum_embedding_input, candidate_embedding_biases])
model = Model(input=[context_words_input, target_word_input], outputs=softmax)
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
def train(self):
self.process_corpus()
model = self.get_cbow_model()
model.fit_generator(self.get_batch_data(),
steps_per_epoch=self.sentence_number / self.BATCH_SIZE,
epochs=self.EPOCH_NUMBER,
workers=self.WORKER_NUMBER,
use_multiprocessing=True
)
model.save_weights(self.model_save_path)
embeddings = model.get_weights()[0]
self.normalized_embeddings = embeddings / ((embeddings ** 2).sum(axis=1).reshape((-1, 1)) ** 0.5)
f_word_index = open("word_index.txt", "w")
f_word_embedding = open("word_embedding.txt", "w")
for word in self.word_id_map.keys():
f_word_index.write(str(word) + "\t" + str(self.word_id_map[word]) + "\r\n")
emb = self.normalized_embeddings[self.word_id_map[word]]
emb = [str(v) for v in emb]
f_word_embedding.write(word + "\t" + "\t".join(emb) + "\r\n")
f_word_index.close()
f_word_embedding.close()
if __name__ == "__main__":
conf_dict = {
"BATCH_SIZE": 3,
"EPOCH_NUMBER": 20,
"EMBEDDING_SIZE": 256
}
word2vec = Word2vec(conf_dict, "corpus", "w2v.model")
word2vec.train()加载
# coding: utf8
import numpy as np
class WordEmb:
def __init__(self, filename, sep="\t"):
self.word_id_map = dict()
self.id_word_map = dict()
self.lookup = None
self.__load(filename, sep)
def __load(self, filename, sep):
index = 0
id_emb_list = list()
for line in open(filename):
splits = line.rstrip().split(sep)
if len(splits) < 10:
continue
word = splits[0]
emb = [float(item) for item in splits[1:]]
self.word_id_map[word] = index
self.id_word_map[index] = word
index += 1
id_emb_list.append(emb)
self.lookup = np.array(id_emb_list)
def most_similarity(self, word, top_k=10):
if word not in self.word_id_map:
print("word not in embedding dict!")
return list()
v = self.lookup[self.word_id_map[word]]
sims = np.dot(self.lookup, v)
sort = sims.argsort()[::-1]
sort = sort[sort > 0]
return [(self.id_word_map[i], sims[i]) for i in sort[:top_k]]
def answer(self, word1, word2, word3, top_k=10):
if word1 not in self.word_id_map:
print("word1 not in embedding dict!")
return list()
if word2 not in self.word_id_map:
print("word2 not in embedding dict!")
return list()
if word3 not in self.word_id_map:
print("word3 not in embedding dict!")
return list()
v1 = self.lookup[self.word_id_map[word1]]
v2 = self.lookup[self.word_id_map[word2]]
v3 = self.lookup[self.word_id_map[word3]]
v4 = v1 - v2 + v3
sims = np.dot(self.lookup, v4)
sort = sims.argsort()[::-1]
sort = sort[sort > 0]
return [(self.id_word_map[i], sims[i]) for i in sort[:top_k]]
def sim(self, word1, word2):
if word1 not in self.word_id_map:
print("word1 not in embedding dict!")
return None
if word2 not in self.word_id_map:
print("word2 not in embedding dict!")
return None
v1 = self.lookup[self.word_id_map[word1]]
v2 = self.lookup[self.word_id_map[word2]]
return np.dot(v1, v2) / (np.linalg.norm(v1) * (np.linalg.norm(v2)))效果
加载
wordemb = WordEmb("data/wordemb/word_embedding.txt")与腾讯最相近的词

与海淀区最相近的词
