目录
图形化描述
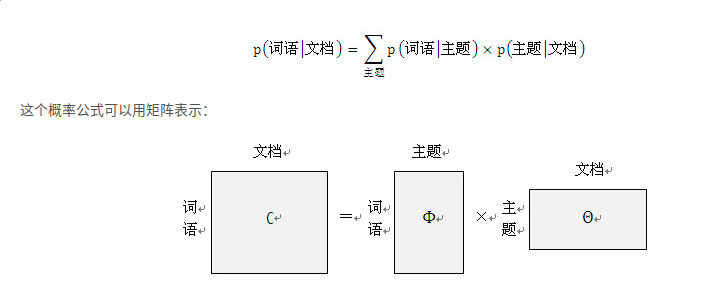
Unigram Model
产生文本流程
- 上帝只有一个骰子,这个骰子有V个面,每个面对应一个词,各个面的概率不一
- 每抛一次骰子,抛出的面就对应产生一个词;如果一篇文档中有n个词,上帝就是独立的抛n词骰子产生这n个词
生成过程图形化
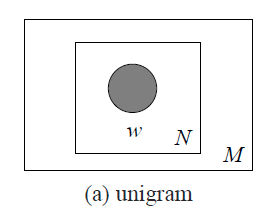
Mixture of unigram
图形化表示
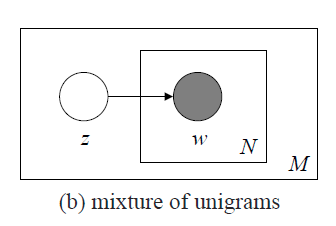
从上图可以看出,z在w所在的长方形外面,表示z生成一份N个单词的文档时主题z只生成一次,即只允许一个文档只有一个主题,这不太符合常规情况,通常一个文档可能包含多个主题。
LDA(潜在狄利克雷分配)
生成过程
Chooseparameter θ ~ p(θ);
For each ofthe N words w_n:
Choose a topic z_n ~ p(z|θ);
Choose a word w_n ~ p(w|z);
其中θ是一个主题向量,向量的每一列表示每个主题在文档出现的概率,该向量为非负归一化向量;p(θ)是θ的分布,具体为Dirichlet分布,即分布的分布;N和w_n同上;z_n表示选择的主题,p(z|θ)表示给定θ时主题z的概率分布,具体为θ的值,即p(z=i|θ)= θ_i;p(w|z)同上。
图形化表示
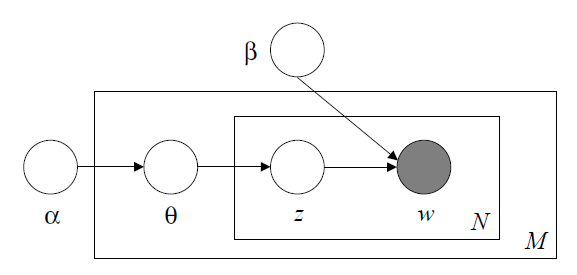
计算
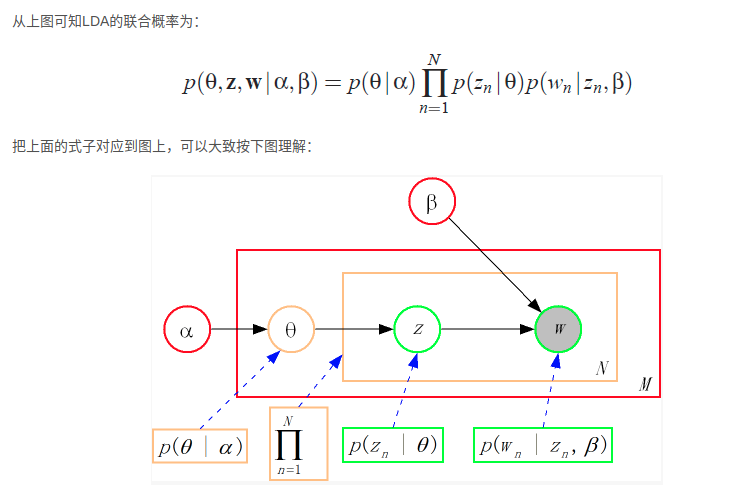
从上图可以看出,LDA的三个表示层被三种颜色表示出来:
- corpus-level(红色):α和β表示语料级别的参数,也就是每个文档都一样,因此生成过程只采样一次。
2.document-level(橙色):θ是文档级别的变量,每个文档对应一个θ,也就是每个文档产生各个主题z的概率是不同的,所有生成每个文档采样一次θ。
- word-level(绿色):z和w都是单词级别变量,z由θ生成,w由z和β共同生成,一个 单词w对应一个主题z。
通过上面对LDA生成模型的讨论,可以知道LDA模型主要是从给定的输入语料中学习训练两个控制参数α和β,学习出了这两个控制参数就确定了模型,便可以用来生成文档。其中α和β分别对应以下各个信息:
α:分布p(θ)需要一个向量参数,即Dirichlet分布的参数,用于生成一个主题θ向量;
β:各个主题对应的单词概率分布矩阵p(w|z)。
把w当做观察变量,θ和z当做隐藏变量,就可以通过EM算法学习出α和β,求解过程中遇到后验概率p(θ,z|w)无法直接求解,需要找一个似然函数下界来近似求解,原文使用基于分解(factorization)假设的变分法(varialtional inference)进行计算,用到了EM算法。每次E-step输入α和β,计算似然函数,M-step最大化这个似然函数,算出α和β,不断迭代直到收敛。