《Actions Speak Louder than Words:Trillion - Parameter Sequential Transducers for Generative Recommendations》
总结
作者为Jiaqi Zhai、Lucy Liao、Xing Liu等人,来自Meta AI。
一、研究背景
- 大规模推荐系统面临高基数、异构特征和处理海量用户行为的挑战,现有深度学习推荐模型(DLRM)在计算上难以扩展。
- 受Transformers在语言和视觉领域的成功启发,作者重新审视推荐系统的基本设计选择,将推荐问题重新表述为生成式建模框架内的序列转导任务。
二、从DLRM到GRs:推荐作为序列转导任务
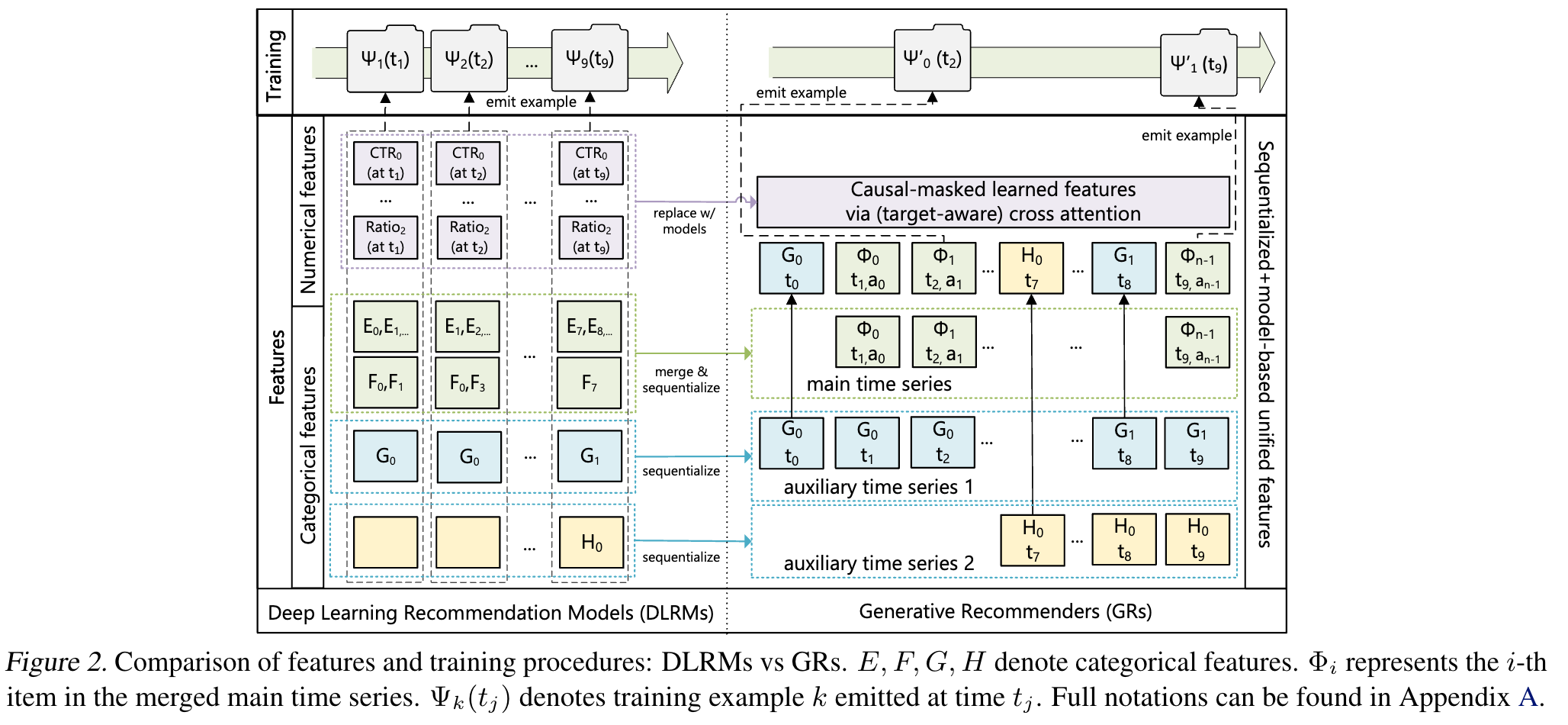
- 统一DLRM中的异构特征空间:将DLRM中的分类(稀疏)和数值(密集)特征整合为单一统一的时间序列。
- 将排名和检索重新表述为序列转导任务:在因果自回归设置中,将标准的排名和检索任务定义为序列转导任务,通过交错项目和动作来实现排名任务的目标感知交叉注意力。
- 生成式训练:从传统的印象级训练转变为生成式训练,降低计算复杂度,使编码器成本在多个目标之间分摊。
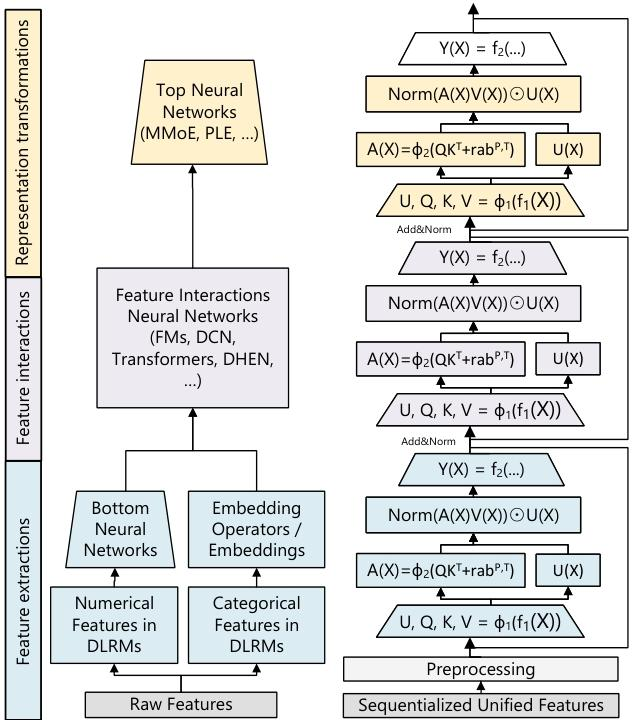
三、用于生成式推荐的高性能自注意力编码器(HSTU)
- 设计:HSTU由通过残差连接的相同层堆叠而成,包括点式投影、空间聚合和点式变换三个子层。
-
特点:
-
点式聚合注意力:采用新的点式聚合(归一化)注意力机制,能够捕捉用户偏好强度和处理非平稳词汇。
- 利用和算法增加稀疏性:通过Stochastic Length(SL)算法和高效的注意力内核,利用并增加用户历史序列的稀疏性,提高编码器效率。
- 最小化激活内存使用:简化设计,减少线性层数和融合计算,降低激活内存使用,使网络能够构建更深的层次。
- 通过成本分摊扩展推理:提出M - FALCON算法,通过修改注意力掩码和偏差,使模型复杂度能够随着候选数量线性扩展,同时利用编码器级的KV缓存提高推理效率。
四、实验
-
验证HSTU编码器的归纳假设:
-
传统序列设置:在MovieLens和Amazon Reviews数据集上的实验表明,HSTU在相同配置下显著优于基线,且扩大规模后性能进一步提高。
- 工业规模流媒体设置:在工业规模数据集上的实验表明,HSTU在排名和检索任务中均优于Transformers,且具有更好的扩展性和效率。
- 编码器效率:SL在不降低模型质量的前提下,允许高稀疏性以降低训练成本;HSTU在训练和推理效率上比Transformers有显著提升,且能构建更深的网络。
- Generative Recommenders(GRs)与DLRM在工业规模流媒体设置中的比较:GRs不仅在离线任务中显著优于DLRM,而且在A / B测试中带来了12.4%的指标提升;GRs能够通过其架构和统一的特征空间有意义地捕获DLRM中使用的特征;在大规模工业设置中,GRs展示出比DLRM更好的扩展性,且遵循计算量的幂律缩放。
五、相关工作
- 先前关于序列推荐的工作主要将用户交互简化为基于项目的单一同质序列,工业应用主要采用成对注意力或序列编码器作为DLRM的一部分,多阶段注意力被用于提高效率,生成式方法在检索中被探索。
- 高效注意力是一个主要的研究焦点,近期的研究包括替代的序列转导设置、硬件感知的公式化以减少内存使用和提高运行时间,以及利用大语言模型进行推荐任务的相关工作。
六、结论
- 提出了Generative Recommenders(GRs)这一新范式,将排名和检索表述为序列转导任务,并通过新的HSTU编码器设计和训练推理算法,使GRs能够以生成的方式进行训练。
- GRs和HSTU在生产中取得了12.4%的指标改进,并且比传统DLRM具有更好的扩展性能。
- 用户行为在生成式建模中是一种未被充分探索的模态,GRs的特征简化为推荐、搜索和广告的第一个基础模型铺平了道路,其完全序列的设置使推荐能够在端到端的生成式环境中进行表述,从而更好地全面协助用户。
七、影响声明
- 减少推荐、搜索和广告系统对大量异构特征的依赖,可以使这些系统更加隐私友好,同时改善用户体验。
- 通过完全序列的公式化,推荐系统能够将用户的长期结果归因于短期决策,减少网络上不符合用户长期目标的内容(包括点击诱饵和假新闻)的流行,更好地使平台的激励与用户价值保持一致。
- 基础模型和缩放定律的应用有助于减少推荐、搜索和相关用例所需的模型研究和开发的碳足迹。
训练深度学习模型的总计算量的折线图
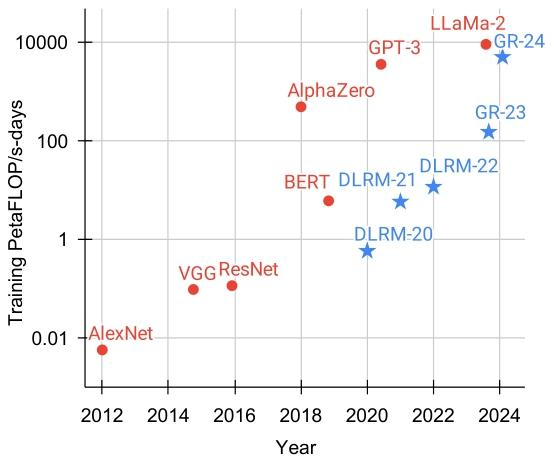
这是一张展示多年来用于训练深度学习模型的总计算量的折线图。图表的横轴表示年份,从2012年到2024年;纵轴表示训练的PetaFLOP(每秒千万亿次浮点运算),范围从0.01到10000。
图中有两种类型的数据点:红色圆点和蓝色星形。红色圆点代表一些知名的深度学习模型,包括AlexNet、VGG ResNet、BERT、AlphaZero、GPT - 3和LLaMa - 2。蓝色星形代表DLRM(深度学习推荐模型)和GR(生成式推荐模型),其中DLRM - 20、DLRM - 21、DLRM - 22是DLRM在2020年、2021年和2022年的数据,GR - 23和GR - 24是GR在2023年和2024年的数据。
从图中可以看出:
- 2012年,AlexNet的训练计算量非常低,接近0.01 PetaFLOP/s - days。
- 随着时间的推移,训练计算量逐年增加。例如,VGG ResNet在2014 - 2016年期间的计算量显著高于AlexNet。
- BERT在2018 - 2020年期间的计算量进一步增加。
- AlphaZero在2018 - 2020年期间的计算量达到了较高水平。
- GPT - 3在2020 - 2022年期间的计算量达到了一个峰值。
- LLaMa - 2在2022 - 2024年期间的计算量也很高。
- DLRM和GR的数据显示,它们在2020 - 2024年期间的计算量也在不断增加,尤其是GR - 24的计算量接近10000 PetaFLOP/s - days。
总体来看,这张图表展示了深度学习模型在过去十几年中所需的训练计算量呈指数级增长的趋势。
符号说明
- $\mathbb{X}$:动态非稳态的词表
- $\mathbb{X}_c$:推荐系统物料(图文/视频),是$\mathbb{X}$的子集
- $x_0,x_1,...,x_{n-1}$:输入的tokens
- $y_0,y_1,...,y_{n-1}$:输出的tokens, yi∈X∪{∅}, 当yi=∅时表示yi的值是undefined的。
- ai与Φi∈Xc (Xc⊆X): 用户行为行为(如收藏,完播等), 以及行为所对应的内容(如视频,商品)
- t0,t1,...,tn−1: 行为所对应的时间点
- m0,m1,...,mn−1: 掩码序列, m∈{0,1}, 当mi=0时表示yi的值是undefined的。
M - FALCON算法
M - FALCON全称为Microbatched - Fast Attention Leveraging Cacheable OperatioNs(利用可缓存操作的微批次快速注意力),是论文中提出的一种用于推荐系统推理阶段的算法,主要目的是解决在处理大量候选时的计算效率问题,具体内容如下:
-
并行处理与成本降低
-
M - FALCON通过修改注意力掩码,能够在推理时并行处理$b_m$个候选,从而将应用交叉注意力的成本从$O(b_m n^2 d)$降低到$O((n + b_m)^2 d)$。在实际的推荐系统中,当处理排名任务时,往往需要对大量的候选项目进行评估,这种并行处理方式能够显著提高效率。例如,在处理数千个候选项目时,传统方法可能需要逐个计算每个候选项目与用户历史行为序列的注意力得分,计算成本随着候选项目数量的增加而急剧增加($O(b_m n^2 d)$)。而M - FALCON通过巧妙的注意力掩码修改,使得在一次前向传播中,可以同时处理多个候选项目,并且保证计算结果与逐个处理时相同,将计算成本降低到$O((n + b_m)^2 d)$,当$b_m$相对$n$较小时,计算成本近似为$O(n^2 d)$,大大提高了推理速度。
-
微批次处理与缓存利用
-
该算法将总体的$m$个候选划分为$\lceil m / b_m\rceil$个微批次,每个微批次大小为$b_m$。在处理大量候选时,这种微批次处理方式能够更好地利用计算资源。同时,它可以利用编码器级的键值(KV)缓存,在微批次内和跨请求之间共享计算结果。例如,在一个在线推荐系统中,当不同用户请求推荐时,可能会有部分用户历史行为序列是相同的,通过KV缓存,可以避免重复计算这部分相同的序列,减少计算冗余。对于每个微批次,只需要计算最后$b_m$个令牌的$U(X)$、$Q(X)$、$K(X)$和$V(X)$,而对于包含$n$个令牌的序列化用户历史,可以重用缓存的$K(X)$和$V(X)$,从而将缓存前向传播的计算复杂度降低到$O(b_m d^2 + b_m n d)$,相比传统方法($O((n + b_m)d^2+(n + b_m)^2d)$)提高了2 - 4倍的效率。
-
广泛适用性
-
M - FALCON不仅适用于基于HSTU的生成式推荐器(GRs),还广泛适用于其他基于自注意力架构的目标感知因果自回归设置的推理优化。这意味着该算法在推荐系统领域具有较高的通用性,只要是符合这种架构特点的模型,都可以利用M - FALCON来提高推理效率,为不同类型的推荐系统提供了一种有效的优化策略。
Figure
Figure2