| 原文发表于 2022-08-26
背景
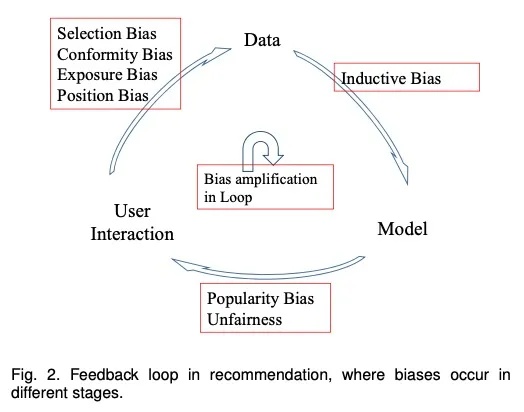
推荐系统中存在非常多的偏差问题,典型的有:
- 选择偏差
- 位置偏差
- 曝光偏差
- 流行度偏差
偏差存在于推荐系统反馈循环的每个阶段中,如下图【摘自网上,如侵必删】所示:
de bias方法
- 样本层面:TopK样本随机展现,将TopK样本做随机展现。 生成无pos bias的样本,把这些样本加到训练模型里,一定程度上降低bias的影响。
- 模型层面:可以将bias特征单独作为一个塔,最后跟非主塔相乘或者相加来产生最终的输出并计算loss,如谷歌YouTuBe的视频多任务中的MMoE解法。
- 特征层面:如果特征是动态的统计特征,可以在特征统计的层面引入de bias. 比如将点展比升级为点检比。两者的区别是: 假如展现了5条结果,用户最后一条点击的结果是第3条结果,则这5条结果的展现全为1, 但当考虑exam(检)时,会认为只有前3条结果被exam了,即前3条结果的exam为1,后2条结果的exam为0. 这样算出来的点检比一般会比点展比效果更好一些。
推荐系统常见的debias方法
- https://zhuanlan.zhihu.com/p/380753374
基于交叉成对排序的无偏推荐算法
- WWW2022
- https://zhuanlan.zhihu.com/p/506167780
参考
- https://zhuanlan.zhihu.com/p/293050486
- https://zhuanlan.zhihu.com/p/375531396