目录
论文地址
总结
《Transformer Quality in Linear Time》总结
这篇论文由Weizhe Hua等人撰写,提出了一种名为FLASH的新模型,旨在解决Transformers在处理长序列时的局限性,同时提高训练效率和模型质量。
-
引言
- Transformers在处理长序列时受限于二次复杂度,许多加速方法存在质量下降、实际开销大或训练低效等问题。
- 本文提出的FLASH模型首次在质量上与完全增强的Transformers相当,且在现代加速器上具有真正的线性可扩展性。
-
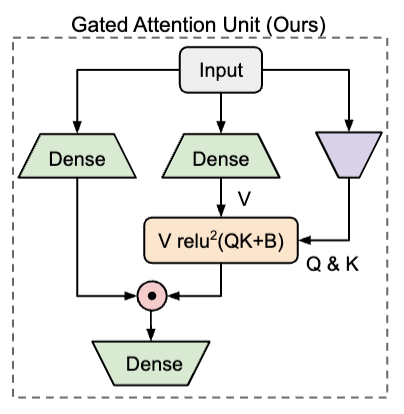
门控注意力单元(GAU)
- 相关层介绍:包括Vanilla MLP、Gated Linear Unit(GLU)。
- GAU定义:将注意力和GLU统一为一层,共享计算,使用更简单/弱的注意力机制,且softmax可简化为常规激活函数。
- GAU与Transformers对比:在不同模型规模和短上下文长度(512)的实验中,GAUs与Transformers具有竞争力,且两者在局部都是最优的。
-
Fast Linear Attention with GAU
- 现有线性复杂度变体的问题:部分注意力方法涉及不规则或规则的内存重新格式化操作,对现代加速器不友好;线性注意力在自回归训练中效率低下。
- 混合块注意力(Mixed Chunk Attention):结合局部注意力和全局注意力,减少二次注意力的计算,同时减少传统线性注意力中的RNN风格步骤,实现快速的自回归训练。
-
实验
- 模型与基线:包括二次复杂度模型FLASH - Quad和线性复杂度模型FLASH,基线包括 vanilla Transformer、Transformer + RoPE(Transformer + )和 Transformer + RoPE + GLU(Transformer ++ ),以及Performer和Combiner。
- 双向语言建模:在C4数据集上进行,FLASH - Quad在所有上下文长度上都比Transformer和Transformer ++ 更快,且所有模型在512到8192的序列长度上都能达到最佳质量。
- 自回归语言建模:在Wiki - 40B和PG - 19数据集上进行,FLASH - Quad和FLASH在训练延迟方面表现最佳,且在质量 - 训练速度权衡方面优于其他模型。
- 微调:在TriviaQA数据集上进行微调,FLASH家族的微调结果可通过一些模型配置的改变而受益。
- 消融研究:包括对局部二次注意力和全局线性注意力贡献的研究,对使用GAU重要性的研究,以及对块大小影响的研究。
-
结论
- FLASH通过设计高性能层(门控线性单元)和结合加速器高效的近似策略(混合块注意力),解决了现有高效Transformer变体的质量和经验速度问题。
- 未来工作将研究这个新模型家族的缩放定律和在下游任务上的性能。
GLU(Gated Linear Unit)
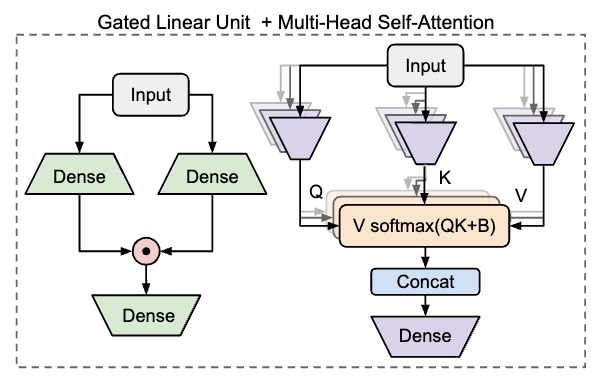
GLU(Gated Linear Unit)公式:
$U=\phi_{u}\left(X W_{u}\right), V=\phi_{v}\left(X W_{v}\right) \in \mathbb{R}^{T × e}$。
$O=(U \odot V) W_{o} \in \mathbb{R}^{T × d}$,其中$\odot$表示元素级乘法。
在GLU中,每个表示$u_i$由与同一标记相关联的另一个表示$v_i$门控。
- 特点及作用:GLU已被证明在许多情况下有效,并被用于最先进的Transformer语言模型中。
GAU(Gated Attention Unit)
| GAU | 代码 |
|---|---|
 |
 |