LoRA简介
LoRA(Low-Rank Adaptation of large language models)
这是一种用于微调大型语言模型的低秩适应技术。它最初应用于自然语言处理(NLP)领域,特别是用于微调 GPT-3 等模型。
其主要特点和工作原理如下:
- 通过仅训练低秩矩阵,然后将这些参数注入到原始模型中,实现对模型的微调。这种方法减少了计算需求,使训练资源比直接训练原始模型小得多,适合在资源有限的环境中使用。
- 对 StableDiffusion 模型中关键的交叉注意力层进行微小改动。交叉注意力层的权重被排列成矩阵形式,LoRA 将其权重添加到这些矩阵中来对模型进行微调。它通过将一个大矩阵分解为两个较小(低秩)的矩阵来减少存储数字,从而使模型文件变小。例如,一个具有 1,000 行和 2,000 列的矩阵(需存储 2,000,000 个数字),可分解为一个 1,000×2 的矩阵和一个 2×2,000 的矩阵,只需存储 6,000 个数字。研究发现,在交叉注意力层中进行这样的操作并不会对微调的效果产生太大影响。
在使用 LoRA 模型时,通常涉及安装插件和配置参数。以在 Automatic1111 StableDiffusion GUI 中的使用为例,首先要将模型文件放入特定文件夹(stable-diffusion-webui/models/lora);使用时,将“lora:文件名:乘数”这样的短语放入提示中,其中“文件名”是 lora 模型的文件名(不包括扩展名),“乘数”是应用于 lora 模型的权重,默认值为 1,设置为 0 将禁用模型。用户可调整乘数来控制效果,也可以同时使用多个 lora 模型,或与嵌入一起使用。
LoRA 模型具有训练速度快、计算需求低、训练权重小等优点。其文件大小适中,训练能力也不错,能够在保持原始模型性能的同时,允许用户根据需要进行定制化调整。
工作原理
LoRA(Low-Rank Adaptation)是一种用于微调大型语言模型的低秩适应技术,它可以让图像生成模型在保持高质量的前提下,变得更高效、更快速。它主要用于大规模预训练模型的微调,通过将权重矩阵分解为低秩矩阵,从而减少训练参数,降低计算开销。在Stable Diffusion中,LoRA被用作一种插件,允许用户在不修改SD模型的情况下,利用少量数据训练出具有特定画风、IP或人物特征的模型。
以下是StableDiffusion模型中LoRA的具体工作原理:
- 数据准备:训练过程中的重要步骤,好的数据集会大大提高模型的性能,质量比数量更重要。需要关注的主要点有:
- 数据质量(抠图):确保图像是准确的、清晰的,没有噪声和其他不必要的干扰因素,需要进行目标识别与抠图。
- 图像尺寸:在训练模型之前,需要将所有的图像调整到同一尺寸,基于sd-1.5一般为512*512。
- 数据标签:每个样本都应该有准确的标签,可以使用多种方法生成标签Tag。
- 数据的多样性:数据集应该包括各种不同的角度和环境条件下的图像。
- 数据数量:至少大于5张,越多越好,一般10-20张够用。
- 模型选择:在开始训练前,需要选择一个适合任务的模型,模型的选择通常取决于任务类型以及计算资源。
- 训练过程:在开始训练前,需要设置一些超参数,这些参数在lora-scripts的train.sh中定义。
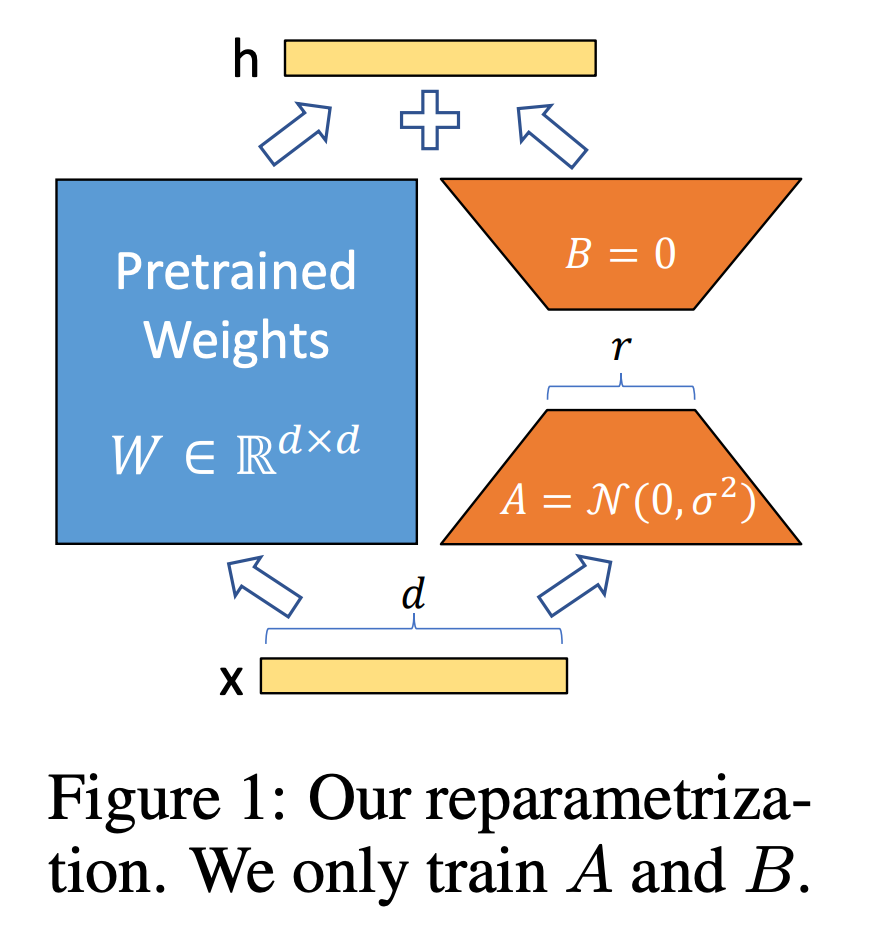
- 推理阶段:正常使用W=W0+BA来更新模型权重。
论文地址
[2106.09685] LoRA: Low-Rank Adaptation of Large Language Models
reparametrization
总结
总的来说,LoRA模型是一种高效、灵活且适用于多种场景的模型微调技术,它在保持原始模型性能的同时,允许用户根据需要进行定制化调整。