论文地址:[2105.01601] MLP-Mixer: An all-MLP Architecture for Vision
模型结构图
总结
《MLP - Mixer: An all - MLP Architecture for Vision》总结
作者为Ilya Tolstikhin等,来自Google Research。
研究背景
计算机视觉中,卷积神经网络(CNNs)一直是主流模型,近期基于自注意力层的Vision Transformers(ViT)也取得了优异性能。本文提出了一种全新的基于多层感知机(MLPs)的架构MLP - Mixer。
主要内容
-
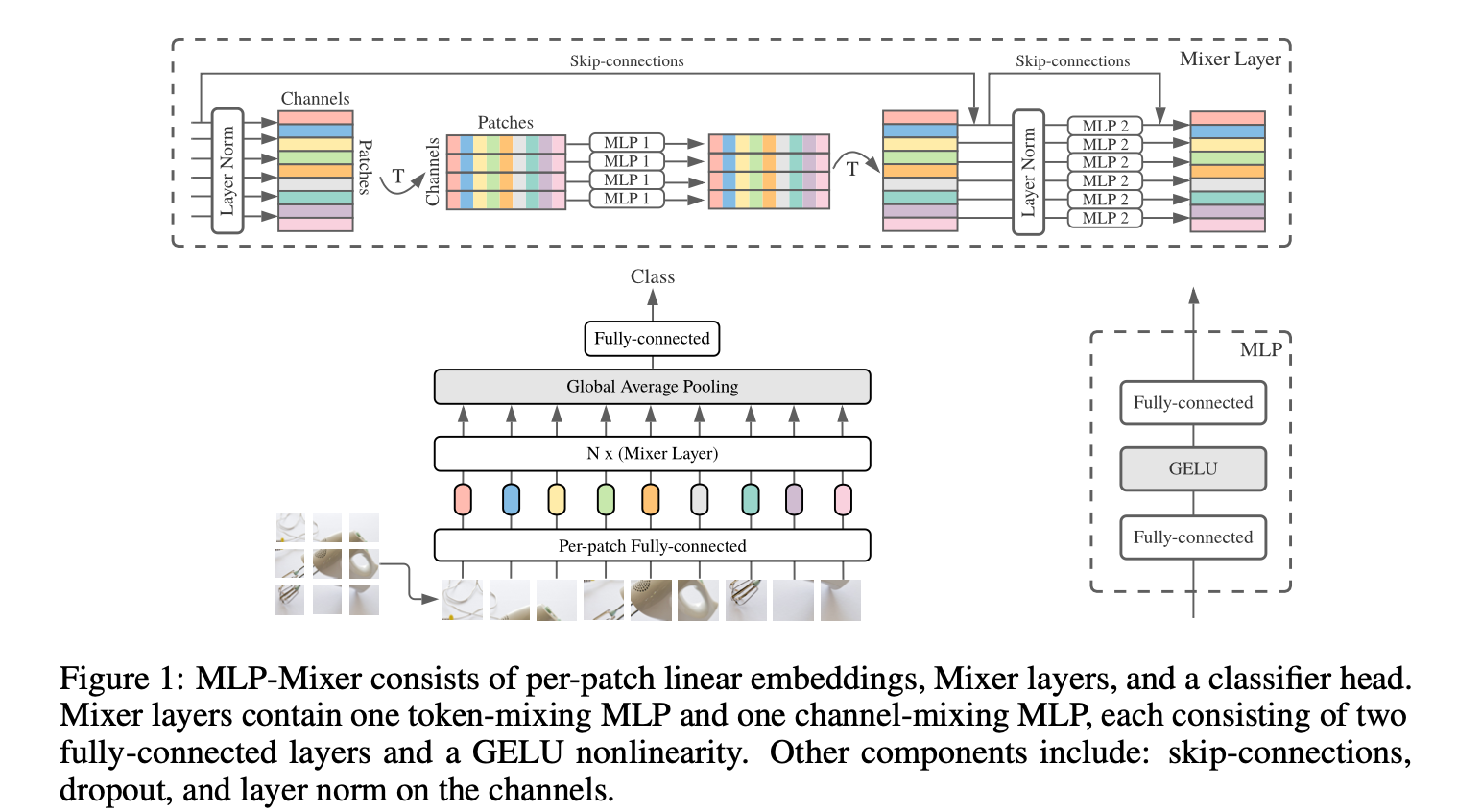
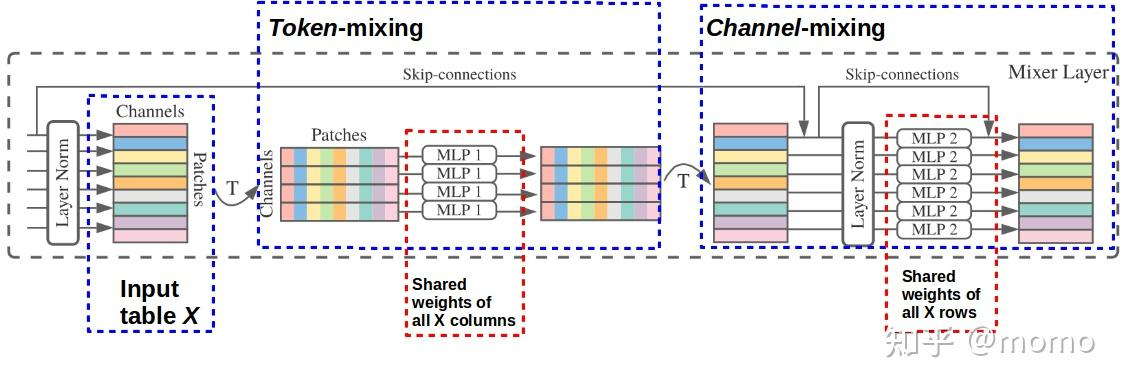
Mixer架构:
- 总体结构:输入为线性投影后的图像块序列(“patches × channels”表),通过两种类型的MLP层进行特征混合,包括通道混合MLPs和令牌混合MLPs,同时使用了一些标准的架构组件,如跳过连接、层归一化等,最后通过全局平均池化层和线性分类器进行分类。
- 具体实现:每个MLP块包含两个全连接层和一个非线性函数,令牌混合MLP对X的列进行操作(应用于转置后的输入表X⊤),通道混合MLP对X的行进行操作。参数绑定防止架构在增加隐藏维度C或序列长度S时增长过快,节省了内存,但对实证性能没有影响。
-
实验:
- 实验设置:在一系列下游分类任务中评估MLP - Mixer模型的性能,包括使用不同的下游任务、预训练数据集、超参数等,并与最先进的CNNs和基于注意力的模型进行比较。
-
主要结果:
- 与其他模型对比:在大规模数据集上预训练时,MLP - Mixer能达到接近最先进的性能,在准确性和计算成本的权衡上具有竞争力;在较小规模数据集上预训练并结合现代正则化技术时,也能取得较好性能,但略逊于专门的CNNs架构。
- 模型规模的影响:随着模型规模的增加,Mixer的性能逐渐提高,在高端模型规模上,Mixer能够与其他模型竞争。
- 预训练数据集大小的影响:预训练数据集越大,Mixer的性能提升越显著,且相比ResNets和ViT,Mixer从数据增长中受益更多。
- 对输入排列的不变性:Mixer对图像块和像素的排列顺序具有不变性,而ResNet的性能会因像素顺序的打乱而显著下降。
- 可视化:Mixer的令牌混合MLPs允许不同空间位置之间的全局信息交换,其学习到的一些特征在整个图像上操作,而另一些在较小区域上操作,深层似乎没有明显可识别的结构,与CNNs类似,存在许多具有相反相位的特征检测器对。
-
相关工作:
- MLP - Mixer的设计思想可以追溯到CNNs和Transformers的相关文献,它将卷积核大小减小到1×1,将卷积转化为标准的密集矩阵乘法(通道混合MLPs),并应用密集矩阵乘法来聚合空间信息(令牌混合MLPs);同时借鉴了近期基于Transformer架构的一些设计选择。
- 许多近期工作致力于设计更有效的视觉架构,Mixer可以看作是在不依赖局部性偏差和注意力机制的方向上迈出的一步。
- 现代最先进的模型通常使用在更大数据集上预训练的权重,或更新的数据增强和训练策略。
结论
MLP - Mixer是一种简单且有效的视觉架构,在准确性和计算资源的权衡方面与现有最先进的方法相当,希望能引发更多关于该架构的研究,包括研究模型学习到的特征以及理解其归纳偏差在泛化中的作用等。