LLM(Large Language Model)基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)是一种训练语言模型的技术,旨在使模型的输出更符合人类的期望和偏好。
该技术的主要步骤包括:
- 数据收集:首先,收集大量的文本数据,用于预训练语言模型。
- 预训练:使用收集到的数据对语言模型进行预训练,使其学习语言的统计规律和语义表示。
- 人类反馈收集:请人类标注者对模型的输出进行评估和反馈,例如判断输出的质量、相关性、准确性等。这些反馈可以以评分、排名或文本注释的形式提供。
- 奖励函数定义:根据人类反馈,定义一个奖励函数,用于衡量模型输出的好坏。奖励函数可以基于人类标注者的反馈来设计,例如,给予高质量输出较高的奖励,给予低质量输出较低的奖励。
- 强化学习训练:使用奖励函数来指导模型的强化学习训练。在训练过程中,模型通过与环境进行交互,尝试生成不同的输出,并根据奖励函数获得相应的奖励。模型的目标是学习到一种策略,能够生成获得高奖励的输出。
- 迭代优化:不断重复步骤 3 到 5,收集更多的人类反馈,优化奖励函数,并进行进一步的强化学习训练,以不断改进模型的性能。
通过这种方式,LLM 可以从人类反馈中学习到如何生成更符合人类期望的输出,提高模型的性能和实用性。
在实际应用中,可以采用多种技术来实现 RLHF,例如使用深度强化学习算法、优化奖励函数的设计、引入对抗训练等。此外,还需要注意数据的质量和多样性,以及人类标注者的可靠性和一致性,以确保训练出的模型具有良好的性能和泛化能力。
图解大模型RLHF系列
图解大模型RLHF系列之:人人都能看懂的PPO原理与源码解读
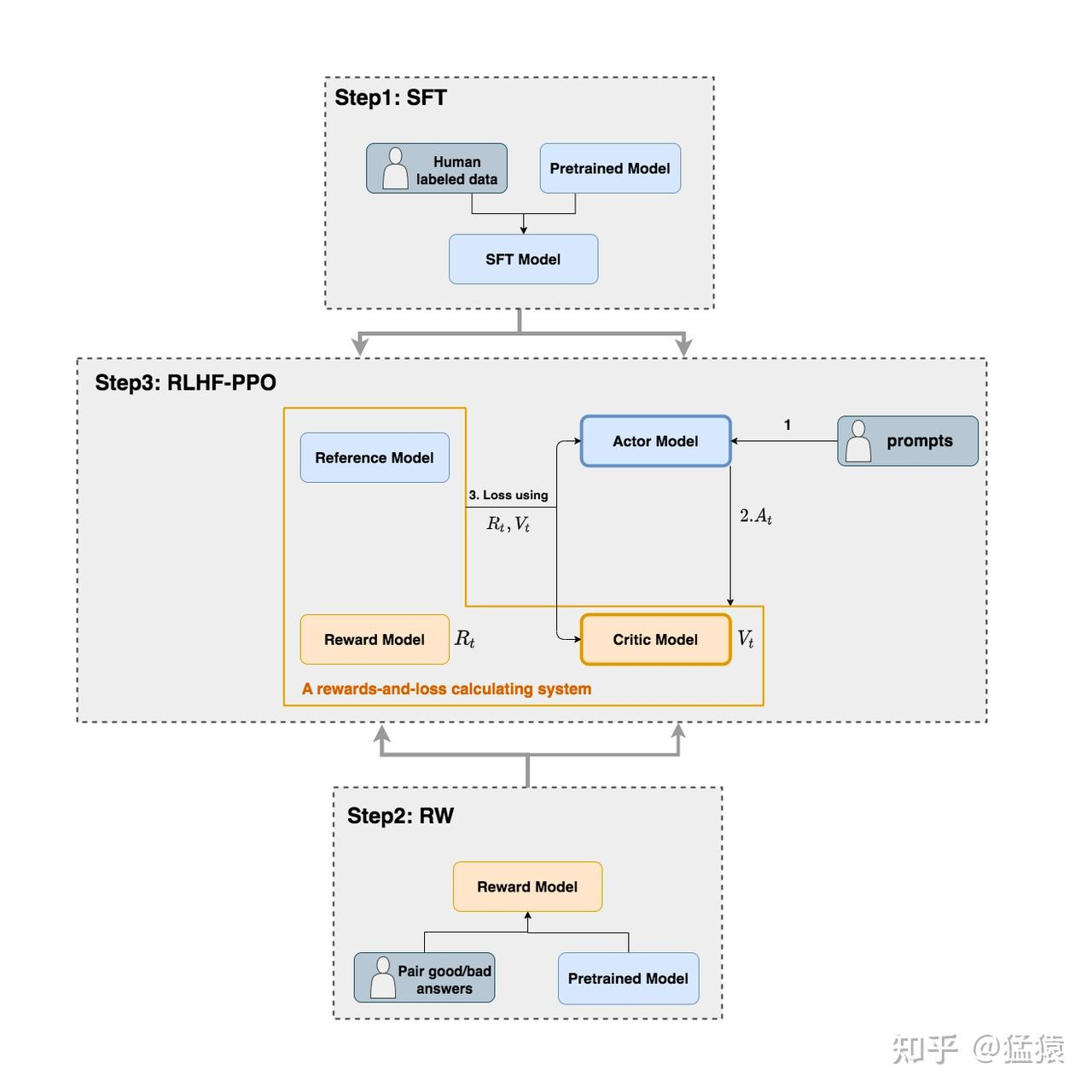
RLHF-PPO
Actor Model
演员模型,这就是我们想要训练的目标语言模型
Critic Model
- Critic Model:评论家模型,它的作用是预估总收益 Vt
Reward Model
- Reward Model:奖励模型,它的作用是计算即时收益 Rt
Reference Model
- Reference Model:参考模型,它的作用是在RLHF阶段给语言模型增加一些“约束”,防止语言模型训歪(朝不受控制的方向更新,效果可能越来越差)