论文地址
[1906.00091] Deep Learning Recommendation Model for Personalization and Recommendation Systems
论文总结
《Deep Learning Recommendation Model for Personalization and Recommendation Systems》论文总结
-
摘要:介绍了一种基于深度学习的推荐模型(DLRM),并提供了在PyTorch和Caffe2框架中的实现。通过特殊的并行化方案减轻内存限制并扩展计算,与现有推荐模型比较,展示了其作为未来算法实验和系统协同设计基准的实用性。
-
引言:
- 个性化和推荐系统广泛应用于互联网公司,近期开始采用神经网络。
- 深度学习模型的架构设计来自推荐系统和预测分析两个视角。
- 本文引入的DLRM模型使用嵌入处理稀疏特征,使用多层感知机(MLP)处理密集特征,并通过统计技术交互这些特征,最后用另一个MLP找到事件概率。
-
模型设计与架构:
-
组件:
- 嵌入(Embeddings):用于处理分类数据,将每个类别映射到抽象空间的密集表示。
- 矩阵分解(Matrix Factorization):通过最小化误差来找到用户和产品的潜在因子表示,嵌入向量的点积可用于预测评级。
- 因子分解机(Factorization Machine):在分类问题中,通过定义包含二阶交互的模型来处理稀疏数据,与支持向量机不同,它能更有效地处理稀疏数据。
- 多层感知机(Multilayer Perceptrons):用于捕获更复杂的交互,在各种应用中广泛使用。
- 架构(DLRM Architecture):结合上述组件的直觉构建,处理分类特征和连续特征,计算不同特征的二阶交互,通过点积连接嵌入向量和处理后的密集特征,最后用MLP和sigmoid函数给出概率。
- 与先前模型的比较:许多深度学习推荐模型使用类似的想法生成高阶项来处理稀疏特征,但DLRM以特定方式交互嵌入,模仿因子分解机,减少模型维度,认为其他网络中的高阶交互可能不值得额外的计算/内存成本。
-
-
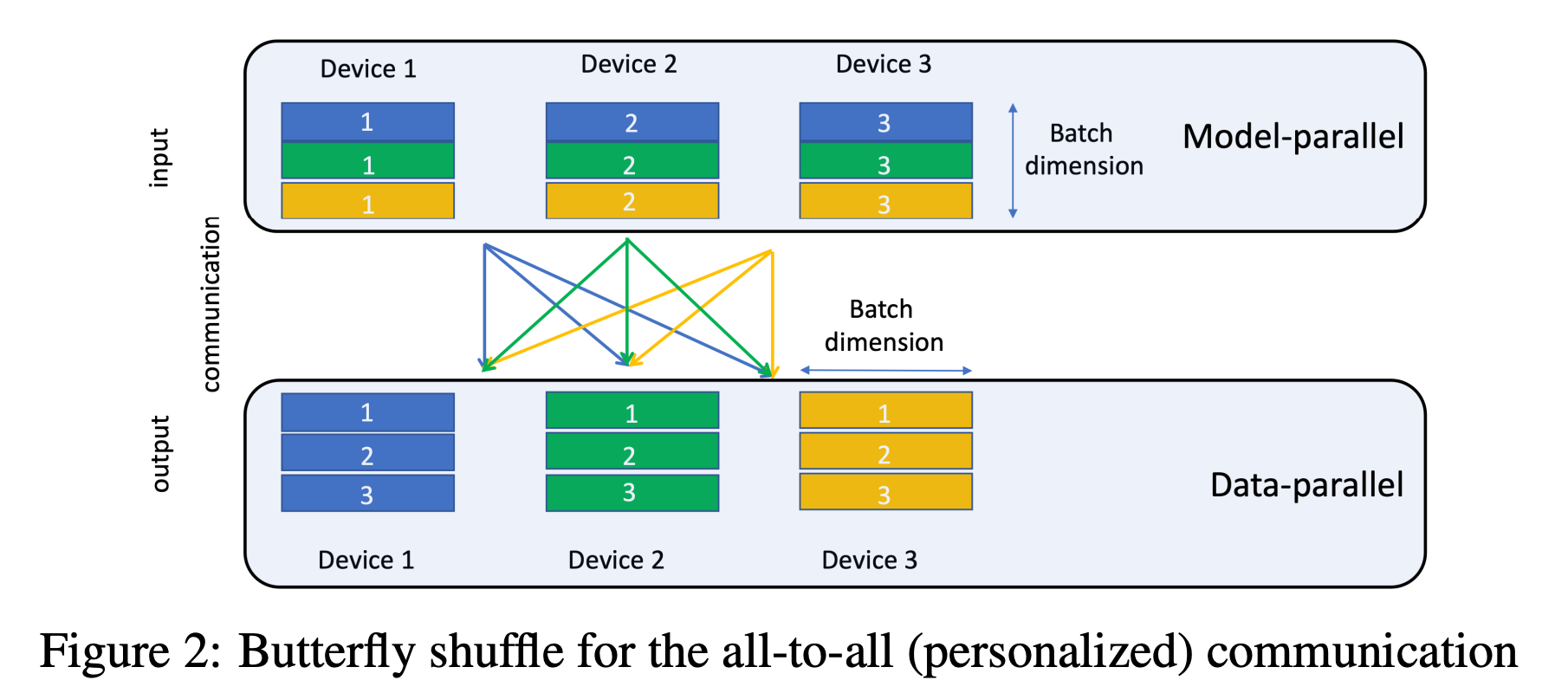
并行化:
- DLRM包含大量参数,训练时间长,需要有效并行化。
- DLRM处理分类特征(嵌入)和连续特征(底部MLP),嵌入占参数大多数且内存密集,MLP参数较小但计算量大。
- 并行化DLRM结合模型并行和数据并行,以减轻嵌入的内存瓶颈并并行化MLP的前向和后向传播,使用自定义实现,计划在后续工作中提供详细性能研究。
-
数据:
- 为了测量模型准确性、测试性能和表征单个算子,需要创建或获取数据集,包括随机、合成和公共数据集。
- 随机数据集:通过生成随机数向量来模拟连续特征,通过确定多热向量中的非零元素数量和生成整数索引来模拟分类特征。
- 合成数据集:支持自定义生成分类特征的索引,可用于保护隐私或研究系统组件,通过记录原始跟踪中的独特访问和重复访问距离的频率来生成合成跟踪。
- 公共数据集:Criteo AI Labs Ad Kaggle和Terabyte数据集是用于广告点击率预测的开源数据集,包含连续和分类特征,通常对连续特征进行简单对数变换,对分类特征进行映射。
-
实验:
- 模型准确性在公共数据集上的表现:在Criteo Ad Kaggle数据集上评估DLRM的准确性,与Deep and Cross网络(DCN)比较,DLRM在未经广泛调优的情况下获得了稍高的训练和验证准确性。
- 模型在单个套接字/设备上的性能:通过一个样本模型在单个套接字设备上进行性能分析,该模型在CPU上运行约256秒,在GPU上运行约62秒,主要时间用于嵌入查找和全连接层。
-
结论:
- 提出并开源了利用分类数据的新型深度学习推荐模型,希望引起对这类网络独特挑战的关注,以促进进一步的算法实验、建模、系统协同设计和基准测试。
结构