论文地址
[2202.06602] Neural Re-ranking in Multi-stage Recommender Systems: A Review
相关模型
论文总结
- 摘要:
本文对多阶段推荐系统中的神经重排序进行了综述,介绍了当前方法的分类,描述了这些方法的发展历程、网络结构、个性化和复杂性,并提供了主要神经重排序模型的基准测试和定量分析,最后讨论了该领域的未来前景。
-
引言:
- 多阶段推荐系统(MRS)广泛应用于各大在线平台,包括候选生成、排名和重排序三个阶段,重排序阶段通过考虑列表上下文来重新排列输入的排名列表,对用户体验和满意度至关重要。
- 随着深度学习的发展,神经重排序成为研究热点并广泛应用于工业界,本文首次对神经重排序进行综述。
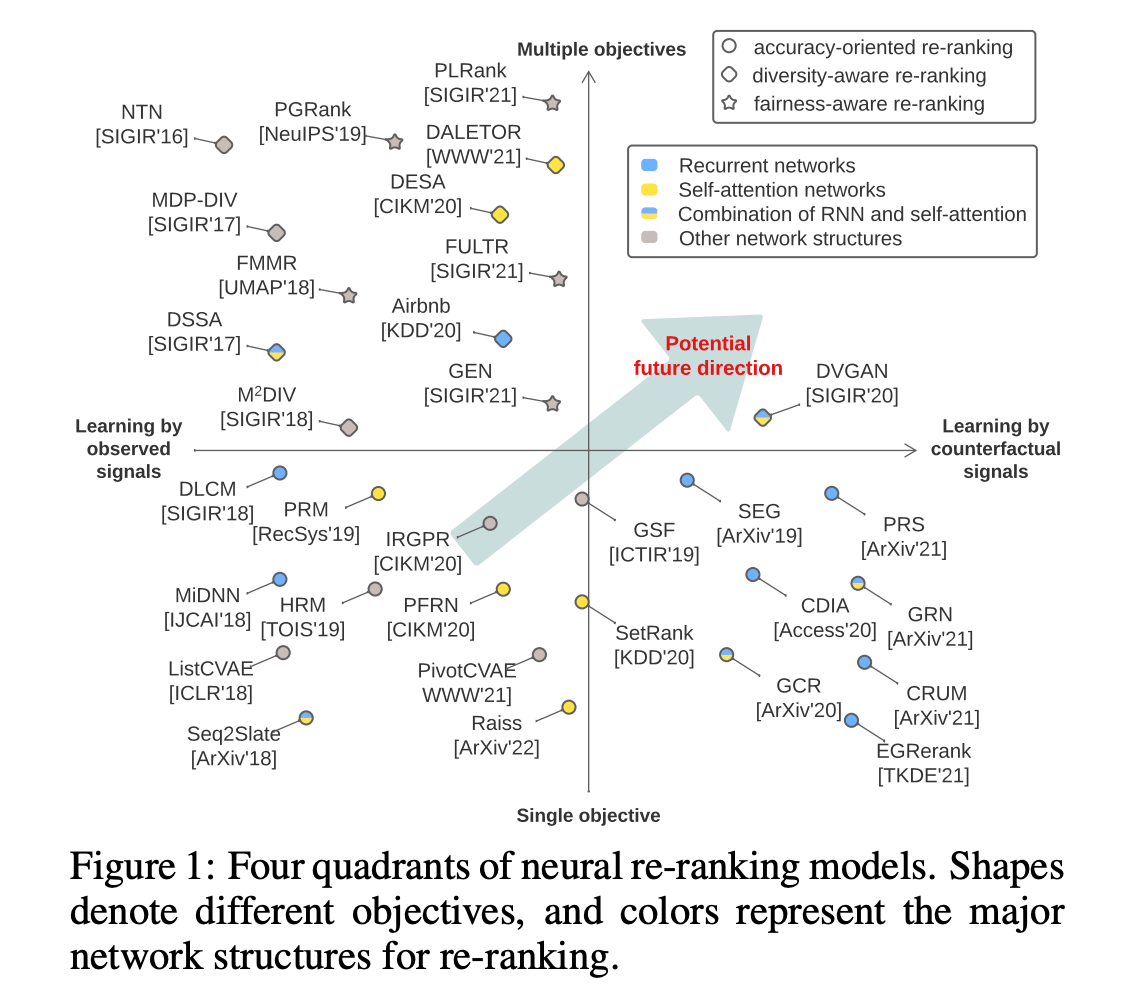
- 本文根据目标(单精度目标或多目标)和监督信号(观察信号或反事实信号)对神经重排序模型进行分类,现有工作存在一些发展特点,如多数研究追求单精度目标、自注意力和RNN与注意力的结合成为流行的网络结构、多目标学习中反事实排列的影响研究较少等。
-
神经重排序推荐:
- 神经重排序通常旨在构建一个多元评分函数,输入是初始排名的整个项目列表,以建模列表上下文/跨项目交互,主要目标是优化准确性,通常用NDCG或MAP等排名指标来衡量,同时鼓励重排序的多样性或公平性也是关键目标之一。
- 根据损失函数的设计,重排序模型可分为单目标和多目标,根据监督信号的来源,可分为学习观察信号和学习反事实信号。
-
单目标:准确性导向:
- 学习观察信号:直接使用初始排名列表R和相应的标签Y来训练模型,网络结构包括递归列表建模(如DLCM、MiDNN、Seq2Slate)、注意力列表建模(如PRM、PFRN、Raiss)和其他结构(如List - CVAE、HRM、IRGPR),这些模型存在潜在的位置或上下文偏差,且只探索了展示给用户的一种排列,限制了选择最优重排序列表的潜力。
- 学习反事实信号:采用评估器 - 生成器范式,通过生成器生成可行的排列,评估器评估每个排列的列表效用,以提供反事实列表的信号,相关研究包括SEG、CDIA、GCR、PRS、GRN、CRUM、EGRerank等,但训练过程复杂,性能依赖于评估器的质量。
- 定性模型比较:从网络结构、优化、个性化和计算复杂性等方面对上述模型进行了比较,发现近年来使用自注意力或RNN与注意力机制结合的重排序模型较为流行,优化方法包括点式(如交叉熵损失)、成对(如BPR损失、铰链损失)和列表式(如Attention Rank损失、KL损失)损失函数,个性化方面有通过输入数据和模型参数两种方式,计算复杂性方面,学习观察信号的模型大多为线性时间复杂度,学习反事实信号的模型复杂度较高。
-
多目标:
- 多样性感知重排序:通过隐式方法(如NTN、MDP - DIV、M2DIV、DALETOR)和显式方法(如DSSA、DVGAN、DESA、Abdool等)来衡量多样性,平衡准确性和多样性的方法包括学习权衡参数或直接优化结合准确性和公平性的特定指标。
- 公平性感知重排序:关注项目公平性,确保每个项目或项目组获得公平的曝光比例,相关研究包括FMMR、PGRank、PLRank、FULTR、GEN等,但神经重排序在这方面的研究相对较少。
-
新兴应用:
- 集成重排序:输入从单个列表扩展到多个列表,相关研究包括DHANR、Xie等、DEAR、Liao等,旨在解决不同来源/渠道的项目混合展示问题。
- 边缘重排序:在云到边缘的框架中,EdgeRec通过在边缘进行实时计算来捕捉用户偏好,提升推荐性能,为设备上的个性化模型或联邦学习带来了有趣的研究课题。
-
实验:
- 介绍了重排序库LibRerank,用于自动化重排序实验和集成主要的重排序算法,使实验结果更具可重复性。
- 在两个公共推荐数据集上进行了基准测试,结果表明重排序算法有效,具有自注意力结构的算法效果更好,EG框架的鲁棒性有待提高。
-
总结和未来展望:
- 神经重排序在科学挑战和工业需求的推动下不断发展,许多研究已应用于工业界,但仍存在一些挑战和开放问题,如稀疏反馈、个性化多样性/公平性、多目标权衡和联合训练等。
综上所述,本文对神经重排序进行了全面的综述,为未来的研究提供了方向。