框架图
论文地址
[1808.09781] Self-Attentive Sequential Recommendation
论文总结
“Self-Attentive Sequential Recommendation”由Wang-Cheng Kang和Julian McAuley撰写,提出了一种基于自注意力的顺序模型SASRec,用于下一项推荐,能平衡模型简约性和复杂性,在不同密度数据集上表现出色且高效。
-
研究背景
- 顺序推荐系统的挑战:从顺序动态中捕获有用模式具有挑战性,因为输入空间维度随过去动作数量呈指数增长。
- 现有方法的局限:马尔可夫链(MCs)在高稀疏性设置中表现良好,但可能无法捕获复杂动态;循环神经网络(RNNs)需要大量数据,在数据密集时表现更好。
-
研究目的:提出SASRec模型,结合RNN和MC的优点,既能捕捉长期语义,又能基于少量相关动作进行预测,同时提高效率。
-
方法
-
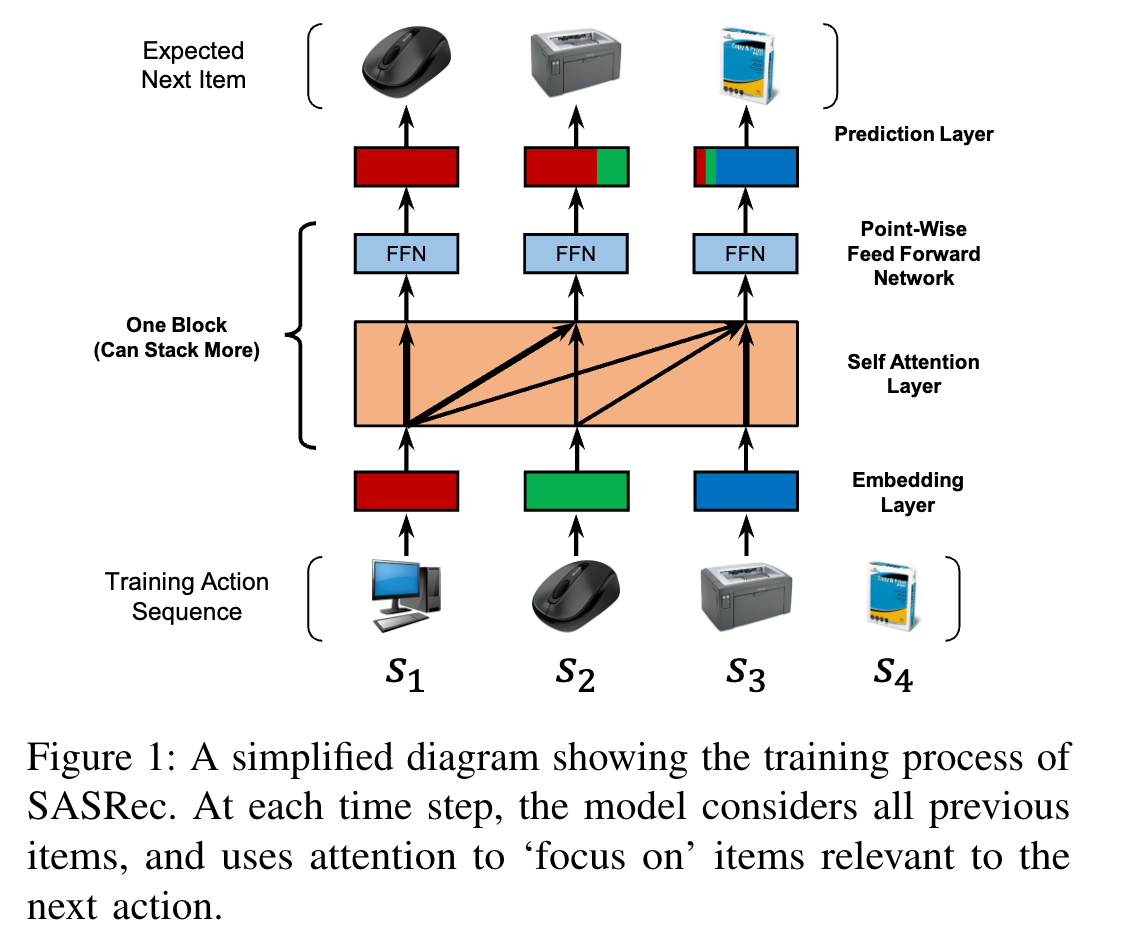
模型架构
- 嵌入层:将用户动作序列转换为固定长度序列,使用项目嵌入矩阵和可学习的位置嵌入。
- 自注意力块:包含自注意力层、因果关系处理、逐点前馈网络,可堆叠多个以学习复杂项目转换。
- 预测层:采用MF层预测下一个项目,可选择共享项目嵌入或添加显式用户嵌入,但实验发现添加显式用户嵌入未提升性能。
- 网络训练:使用二元交叉熵损失作为目标函数,通过Adam优化器进行优化,在训练时随机生成负样本。
- 复杂度分析:空间复杂度适中,时间复杂度主要源于自注意力层和前馈网络,计算可并行化,比RNN和CNN方法快十多倍,能处理几百长度的序列,但对非常长的序列仍需进一步研究。
- 与现有模型的关系:SASRec可视为一些经典CF模型的推广,能自适应关注相关先前项目,解决MC方法中阶数需预先指定的问题,且相比RNN模型在学习长距离依赖时有优势。
-
-
实验结果
-
实验设置
- 数据集:使用四个来自不同应用的数据集(Amazon Beauty、Amazon Games、Steam、MovieLens - 1M),数据稀疏度不同,进行预处理并划分训练、验证和测试集。
- 对比方法:包括一般推荐方法(PopRec、BPR)、基于一阶马尔可夫链的方法(FMC、FPMC、TransRec)和深度学习顺序推荐方法(GRU4Rec、GRU4Rec +、Caser)。
- 实现细节:SASRec默认使用两个自注意力块,学习位置嵌入,共享项目嵌入,使用Adam优化器,不同数据集设置不同超参数。
- 评估指标:采用Hit Rate@10和NDCG@10评估推荐性能,通过随机采样负样本计算。
- 推荐性能:SASRec在稀疏和密集数据集上均优于所有基线方法,平均命中率提升6.9%,NDCG提升9.6%,模型受益于较大的潜在维度(d≥40)。
- 消融研究:分析各组件影响,如位置嵌入在稀疏数据集上可能有用,共享项目嵌入性能更好,残差连接和Dropout有助于提升性能,堆叠两个自注意力块效果较好,多头注意力在该问题中未提升性能。
- 训练效率和可扩展性:SASRec训练速度快,收敛时间短,在GPU加速下比Caser和GRU4Rec +快十多倍,能有效并行计算,模型性能随最大序列长度n增加而提升,n = 500时性能饱和,n = 600时仍比对比方法快。
- 注意力权重可视化:可视化显示模型能自适应关注不同数据集上的相关项目,对位置敏感且层次化,能识别相似项目并分配较大权重。
-
-
研究结论:SASRec模型在顺序推荐任务中表现优异,未来计划扩展模型以纳入更多上下文信息,并研究处理更长序列的方法。