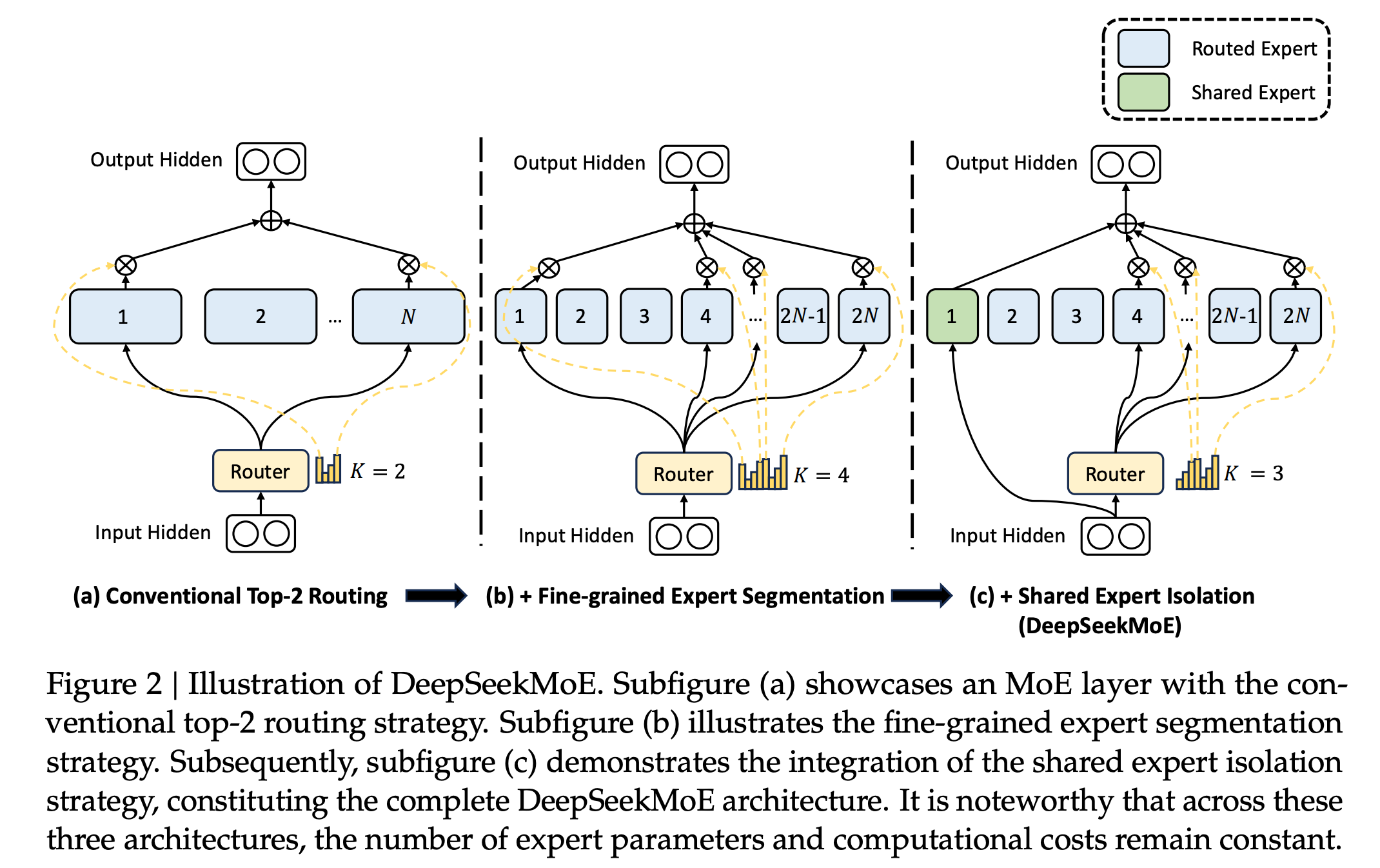
DeepSeek-MOE是指DeepSeek系列模型中采用的一种混合专家模型架构,其核心在于利用多个专门化的专家网络来处理特定类型的数据,并通过门控网络动态选择最适合的专家来提升模型性能。具体来说:
-
架构改进:DeepSeek-MOE在传统MoE架构的基础上进行了两部分改进:
- 细粒度专家切分:将一个专家网络进一步切分为更细粒度的子专家,以避免一个专家覆盖过多领域而导致知识泛化不足。
- 共享专家设计:设计了一些专家在网络运行中始终被激活,作为共享专家,以确保某些公共知识在每次计算中都能被使用。
-
动态路由机制:DeepSeek-MOE通过门控网络根据输入数据的特征动态选择最合适的专家进行处理,而不是激活所有专家,这不仅提高了模型的适应性,也显著降低了计算成本。
-
模块化扩展与分布式训练优化:该架构允许通过增加专家数量或调整专家结构灵活扩展模型规模,同时支持分布式训练,通过并行化处理提升训练效率。
-
突破大模型训练瓶颈:DeepSeek-MOE通过稀疏激活机制缓解了大模型训练中的内存限制和计算开销问题,使得在相同硬件条件下可以训练比密集模型大数倍的参数规模。
-
技术创新:DeepSeek-MOE架构是DeepSeek系列模型的关键技术创新之一,旨在通过混合专家模型的优势,提升模型性能的同时优化计算资源的使用。
-
持续演进:从DeepSeekMoE(V1)到DeepSeek V3,DeepSeek持续在MoE技术上进行创新和优化,包括设备级别的负载均衡、通信负载均衡损失函数等,以应对分布式训练中的挑战。
综上所述,DeepSeek-MOE不仅是一个架构创新,也是DeepSeek系列模型在混合专家模型应用上的重要里程碑。