DeepSeek的Native Sparse Attention(NSA)是一种专为长上下文处理设计的高效注意力机制,旨在解决传统全注意力机制在长序列中计算复杂度高、硬件利用率低的问题。以下是其核心特点和应用场景的总结:
技术特点
-
动态分层稀疏策略
- 粗粒度压缩:将连续的token块聚合成压缩表示(如128-256个token为一组),通过可学习的MLP提取高层语义,减少冗余计算。
- 细粒度选择:基于注意力分数筛选前15%的关键块对(阈值θ=0.35),并在块内保留Top-32的token,剔除80%冗余连接。
- 滑动窗口:独立处理局部上下文(如最近的512个token),确保短程依赖不丢失。
-
硬件协同优化
- 通过CUDA异步拷贝降低内存访问延迟43%,融合QKV投影、稀疏掩码生成等操作减少60%核函数调用。
- 动态负载均衡策略使A100 GPU的SM利用率提升至89%(基线52%)。
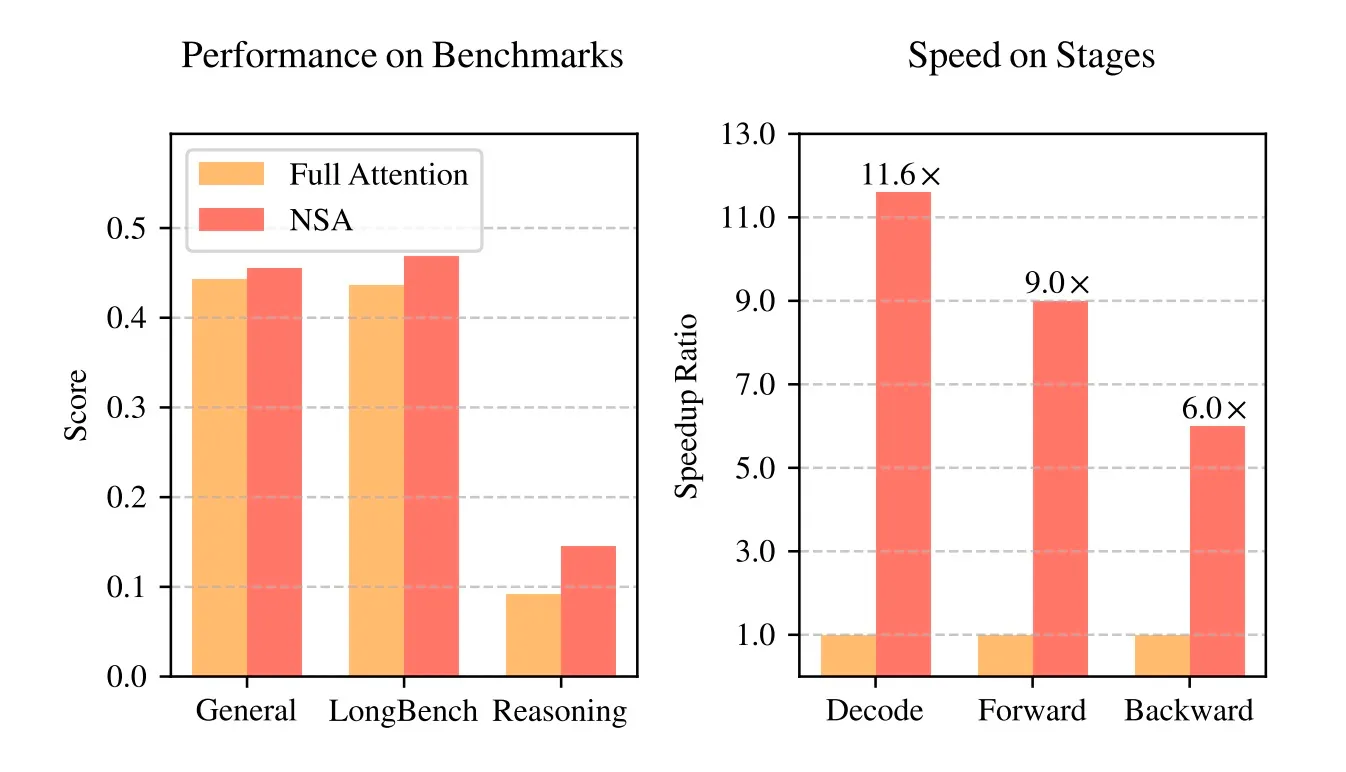
- 实测64k序列解码速度提升11.6倍,前向/反向传播分别加速9倍和6倍。
-
端到端可训练性
- 采用渐进式稀疏训练协议:初期使用稠密注意力,中期逐步引入稀疏结构(稀疏率从30%线性提升至85%),后期固定稀疏模式微调。
- 在The Pile数据集上,LAMBADA准确率达68.2%,较直接稀疏训练提高4.1个百分点。
效果
应用场景
-
智能文档处理
- 合同审查时间从22分钟缩短至6分钟,关键条款漏检率下降65.6%。
- 审计报告生成人工修正量减少58%,但需额外规则校验模块弥补数据引用精度损失。
-
代码仓库分析
- Linux内核代码跨版本比对中,API变更影响链识别率达93%(传统方法78%),误报率仅8%。
- 显存占用从78GB降至41GB,但处理耗时仍需4.3小时(稠密模型9.8小时)。
-
多模态内容生成
- 输入3000字剧本大纲时,角色动机一致性评分提升27%,场景转换流畅度提高19%,但对话情感丰富度略有下降。
优势与挑战
-
优势:在MMLU、GSM8K等基准测试中性能超越全注意力模型,64k长文本检索准确率达100%,硬件加速效果显著。
-
挑战:序列超过128k时稳定性下降,非NVIDIA GPU加速比降低,多任务泛化能力在细粒度推理任务中略逊。
行业影响
NSA通过算法-硬件协同设计,将长文本处理从理论优化推进到工程化落地阶段。其开源生态(如NSA-Compile工具链、专利交叉授权池)推动了行业协作,尤其为企业在法律、医疗、代码开发等领域的长文本应用提供了高效解决方案。未来计划通过混合稀疏架构、跨平台适配和专用语料库进一步提升性能。