论文地址
[2305.13647] Rethinking the Role of Pre-ranking in Large-scale E-Commerce Searching System
论文介绍
《Rethinking the Role of Pre-ranking in Large-scale E-Commerce Searching System》由Zhixuan Zhang等人撰写。文章针对大规模电商搜索系统中预排序的作用进行了重新思考,提出新评估指标和学习框架,有效提升了离线评估效果和在线业务指标。
-
研究背景:淘宝搜索等大规模电商搜索系统采用多阶段排序,预排序是其中关键一环,负责从海量候选商品中筛选出数千个商品,供后续排序模块进一步处理。传统研究将预排序视为小型排序模块,聚焦构建轻量级模型模仿排序模块能力,常用AUC评估,但该指标与在线A/B测试结果不一致。
-
相关工作
- 预排序:多采用向量积DNN模型,如FSCD、RD、COLD、AutoFAS等方法,旨在提升模型排序能力并保证低延迟,常用AUC和hitrate@k评估。
- 排序与匹配:排序模块对预排序输出的商品进行精排,研究多关注网络结构和用户行为建模;匹配模块从海量商品中检索出数十万候选商品,常见方法包括语义匹配、基于行为匹配等。
-
预排序评估指标
- 与排序阶段的一致性:AUC用于衡量排序系统离线指标,在预排序中常用PAUC@10评估与在线排序系统一致性。
- 输出集质量:hitrate@k在匹配阶段用于评估输出集质量,但在预排序中存在问题。提出新指标ASH@k,通过引入其他场景的购买样本构建ASPH@k,能更有效评估预排序输出集质量。
- 淘宝搜索各阶段的全场景购买命中率:实验表明,新预排序模型在ASPH@k和ISPH@k指标上,输出大量商品时优于排序模型;ASPH@k比ISPH@k更可靠,预排序应注重高质量输出。
-
预排序优化
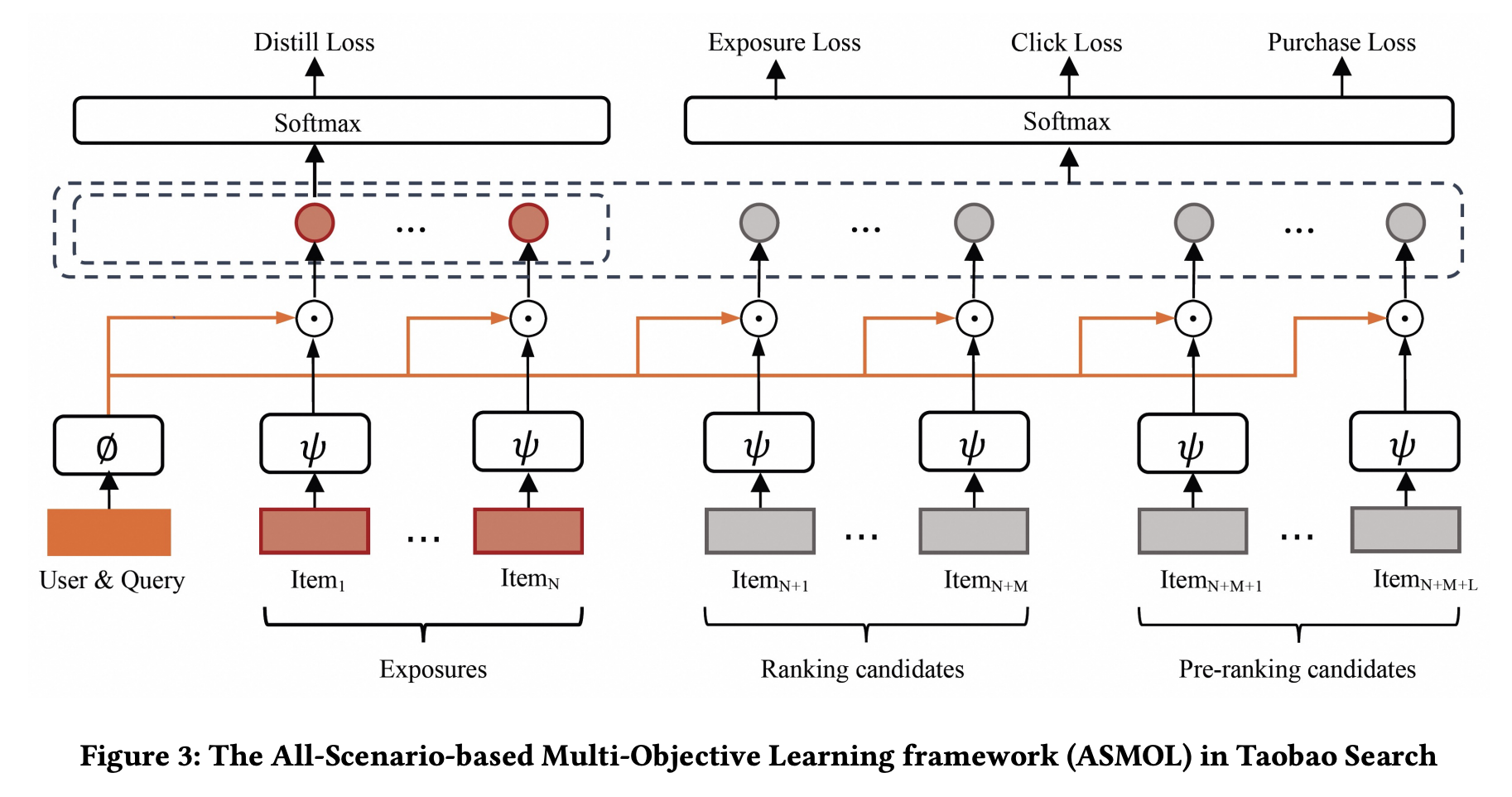
- 多目标学习整体框架(ASMOL):设计全新框架,扩展训练样本并设计蒸馏损失,采用多种标签和结合排序损失与蒸馏损失的函数,以提升预排序输出集质量和与排序阶段的一致性。
- 全空间训练样本:使用包含曝光、排序候选和预排序候选的训练样本,可提升ASPH@3000和在线GMV,不同样本比例会影响模型性能。
- 多目标学习中的全场景标签:消融实验证明全场景标签能有效提升预排序模型在线和离线指标。
- 多正标签的列表式损失:设计多目标损失函数,改进多正标签任务的损失计算方式,实验表明改进后的损失函数在各项指标上表现更优。
- 来自排序阶段的蒸馏:从排序模型蒸馏训练预排序模型时,需谨慎选择蒸馏样本集,实验表明仅学习曝光样本的排序分数有助于预排序达到帕累托最优。
- 多目标组合策略:实验表明,ASMOL单模型策略优于多模型策略,能有效提升离线指标和在线GMV。
-
结论与展望:预排序在电商搜索系统中作用独特,优化时应注重无序输出集质量,使用ASH@k评估,避免盲目模仿排序模型。未来淘宝搜索可基于ASH@k改进排序系统学习框架。