目录
简介
Actor 的前生是 Policy Gradients, 这能让它毫不费力地在连续动作中选取合适的动作, 而 Q-learning 做这件事会瘫痪.
Critic 的前生是 Q-learning 或者其他的 以值为基础的学习法 , 能进行单步更新, 而传统的 Policy Gradients 则是回合更新, 这降低了学习效率.
算法流程图
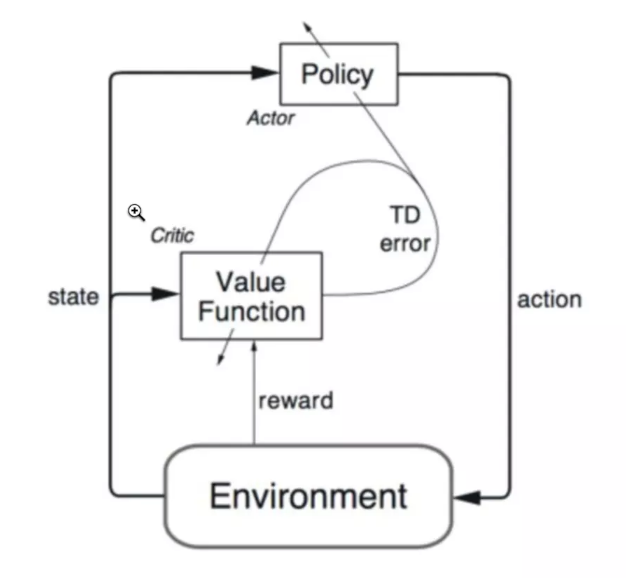
缺点
Actor-Critic 涉及到了两个神经网络, 而且每次都是在连续状态中更新参数, 每次参数更新前后都存在相关性, 导致神经网络只能片面的看待问题, 甚至导致神经网络学不到东西。
Policy算法优缺点
优点
- Better convergence properties (更好的收敛属性)
- Effective in high-dimensional or continuous action spaces(在高维度和连续动作空间更加有效)
- Can learn stochastic policies(可以Stochastic 的策略)
缺点
- Typically converge to a local rather than global optimum(通常得到的都是局部最优解)
- Evaluating a policy is typically inefficient and high variance (评价策略通常不是非常高效,并且有很高的偏差)
value function V(s)
我们再来定义 policy π 的 value function V(s),将其看作是 期望的折扣回报 (expected discounted return),可以看作是下面的迭代的定义:
前状态 s 所能获得的 return,是下一个状态 s‘ 所能获得 return 和 在状态转移过程中所得到 reward r 的加和。