“DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding”介绍了DeepSeek-VL2,这是一系列基于混合专家(MoE)架构的先进视觉语言模型,在性能和效率上较之前的DeepSeek-VL有显著提升,主要通过视觉和语言组件的创新以及数据和训练方法的改进实现,并在多个任务中展现出优异性能。
-
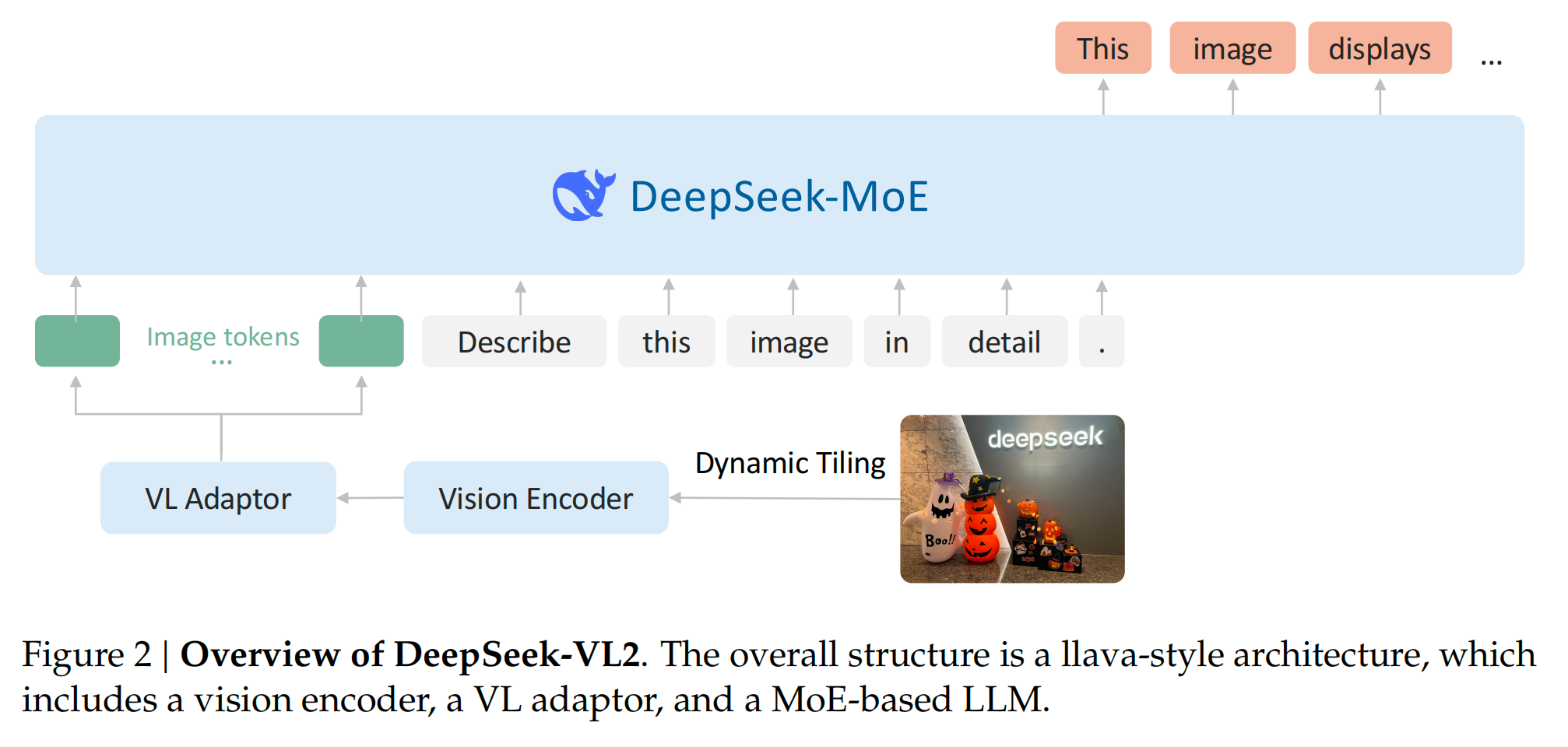
模型架构
- 视觉编码:采用动态切片(dynamic tiling)策略,依据输入图像的分辨率和纵横比将其分割为多个384×384像素的小块及一个全局缩略图块,经SigLIP - SO400M - 384视觉编码器处理,克服了固定分辨率编码器的局限,能有效处理高分辨率和不同纵横比图像,提升视觉理解能力,如在视觉定位、文档/表格/图表分析等任务中表现出色。
- 语言模型:基于DeepSeekMoE,引入多头潜在注意力(MLA)机制压缩Key - Value缓存为潜在向量,结合MoE架构的稀疏计算技术,显著降低计算成本、提高推理效率和吞吐量。模型有DeepSeek-VL2-Tiny、DeepSeek-VL2-Small和DeepSeek-VL2三个变体,激活参数分别为1.0B、2.8B和4.5B。
- 视觉 - 语言适配器:对视觉块处理后,先压缩视觉标记,再添加特殊标记区分全局和局部块,并通过两层多层感知器将视觉序列投影到语言模型嵌入空间,实现视觉与语言信息的有效融合。
-
数据构建
- 训练阶段与数据来源:训练分三个阶段,包括视觉 - 语言对齐、预训练和监督微调。对齐阶段使用ShareGPT4V训练MLP连接器;预训练阶段结合多种来源的视觉 - 语言数据和文本数据,如WIT、WikiHow等,并通过自建数据集和优化图像字幕管道等提升数据质量;监督微调阶段整合开源数据集和高质量内部问答对,并针对不同任务数据进行改进和扩充。
- 数据类型多样:涵盖图像字幕、光学字符识别、视觉问答、视觉定位、基础对话、文本 - 仅数据集等多种数据类型,为模型在不同任务上的学习提供丰富信息,增强模型的泛化和性能表现。
-
训练方法
- 训练流程:按三阶段流水线训练,先固定语言模型训练视觉编码器和适配器,再解锁所有参数进行视觉 - 语言预训练,最后用监督微调数据优化模型指令跟随和对话能力,全程注重视觉理解,仅计算文本标记的下一个标记预测损失。
- 超参数与基础设施:给出详细训练超参数,如学习率、优化器等,并介绍在HAI - LLM平台上针对视觉编码器计算特性采取的负载平衡、并行策略等措施,确保训练高效进行,如不同规模模型在不同节点配置下的训练时长等。
-
模型评估
- 多模态性能基准测试:在DocVQA、ChartQA、InfoVQA等多个常用基准测试集上评估,与LLaVA - OV、InternVL2等先进模型对比,DeepSeek-VL2在激活参数更少的情况下取得相似或更优性能,尤其在视觉定位任务上优势明显。
- 定性研究展示能力:通过实例展示模型在通用视觉问答、梗图理解、多图像对话、视觉故事编写、视觉定位和基础对话等方面的能力,如准确描述图像、理解梗图幽默、基于多图推理、创作故事、定位对象和结合图像文本交互等,但也存在如上下文窗口有限、对模糊图像或未知对象处理待提升、推理能力需加强等局限,为后续研究指明方向。